

Many software developers find they need to store hierarchical data, such as threaded comments, personnel org charts, or nested bill-of-materials. Sometimes it’s tricky to do this in SQL and still run efficient queries against the data. In this blog, I’ll describe several solutions for storing and querying trees in an SQL database, including the design I call Closure Table.
In Closure Table, we store every path in a tree, not only direct parent-child references, but also grandparent-grandchild, and every other path, no matter how long. We even store paths of length zero, which means a node is its own parent. So if A is a parent of B, and B is a parent of C and C is a parent of D, we need to store the following paths: A-A, A-B, A-C, A-D, B-B, B-C, B-D, C-C, C-D, D-D. This makes it easy to query for all descendants of A, or all ancestors of D, or many other common queries that are difficult if you store hierarchies according to textbook solutions.
CREATE TABLE TreePaths (
ancestor CHAR(1) NOT NULL,
descendant CHAR(1) NOT NULL,
length INT NOT NULL DEFAULT 0,
PRIMARY KEY (ancestor, descendant)
) ENGINE=InnoDB;
Because there isn’t much written about using the Closure Table design, I periodically get questions about how to solve certain problems. Here’s one I got this week (paraphrased):
I’m using Closure Table, which I learned about from your book and your presentations. I can neither find nor invent a pure-SQL solution for moving a subtree to a new position in my tree. Right now, I’m reading the nodes of the subtree into my host script, deleting them and re-inserting them one by one, which is awful. Are you aware of a more efficient solution for moving a subtree in this design?
Moving subtrees can be tricky in both Closure Table and the Nested Sets model. It can be easier with the Adjacency List design, but in that design you don’t have a convenient way to query for all nodes of a tree. Everything has tradeoffs.
In Closure Table, remember that adding a node involves copying some of the existing paths, while changing the endpoint for descendant. When you’re inserting a single new node, you just have one descendant to add, joined to all the paths of its ancestors.
Here’s a diagram of a skinny tree lying on its side. A is the root of the tree, and C is the leaf. We want to add new node D.
A -> B -> C …add… D
The Closure Table already has paths A-A, A-B, A-C, B-B, B-C, C-C. You want new paths A-D, B-D, C-D, D-D. Basically you need to copy any path terminating with C (the immediate parent of D), and change the endpoint of that path to D.
That is, copying A-C, B-C, C-C and changing the right C to D gives A-D, B-D, C-D. Then add your reflexive path D-D manually.
INSERT INTO TreePaths (ancestor, descendant, length)
SELECT t.ancestor, 'D', t.length+1
FROM TreePaths AS t
WHERE t.descendant = 'C'
UNION ALL
SELECT 'D', 'D', 0;
The above is the simple case of adding a single new node.
When you insert a subtree, you’re inserting multiple nodes, and you want to create new paths for each one, as many new paths as the number of ancestors of the new location times the number of nodes in the subtree. Suppose A has another child F, and below F we have a subtree D -> E (see illustration):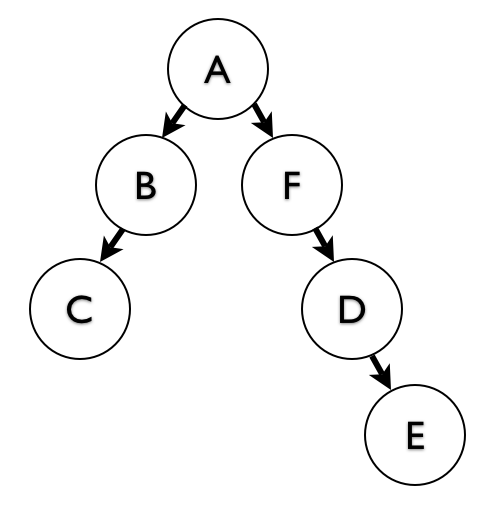
We want to move the subtree starting at D, and place it under B.
Before we move the subtree, we need to disconnect it from its old position in the tree. Delete the outdated paths for the old location of the D subtree (but not the intra-subtree paths). Conceptually, we might try the following SQL statement:
DELETE FROM TreePaths
WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = 'D')
AND ancestor NOT IN (SELECT descendant FROM TreePaths WHERE ancestor = 'D');
But MySQL complains: “You can’t specify target table ‘TreePaths’ for update in FROM clause.” We can’t DELETE and SELECT from the same table in a single query in MySQL. But we can use MySQL’s multi-table DELETE syntax, to find any path that terminate at a descendant of D, but only if the path’s start isn’t also a descendant of D. We do this by using an other join to try to find a third path, starting from D and terminating at the start of the path we want to delete. Only delete when no such third path is found.
DELETE a FROM TreePaths AS a
JOIN TreePaths AS d ON a.descendant = d.descendant
LEFT JOIN TreePaths AS x
ON x.ancestor = d.ancestor AND x.descendant = a.ancestor
WHERE d.ancestor = 'D' AND x.ancestor IS NULL;
That deletes paths that terminate within the subtree (descendants of D), but not paths that begin within the subtree (paths whose ancestor is D or any of descendants of D). So it deletes A-D, A-E, F-D, F-E, but not D-D, D-E, E-E.
To insert the subtree under its new location, we want new paths A-D, B-D, C-D, D-D as well as A-E, B-E, C-E, and D-E. We already have D-E, you just have to not lose that path in the process of moving (same applies to any other intra-subtree paths if it’s larger than just this simple example). We also already have D-D and E-E and any other reflexive paths.
If we were inserting just a single new node, we would hardcode ‘D’ as the id of the new node. But now we need to insert all the nodes of the subtree. We use a Cartesian join between the ancestors of B (going up) and the descendants of D (going down).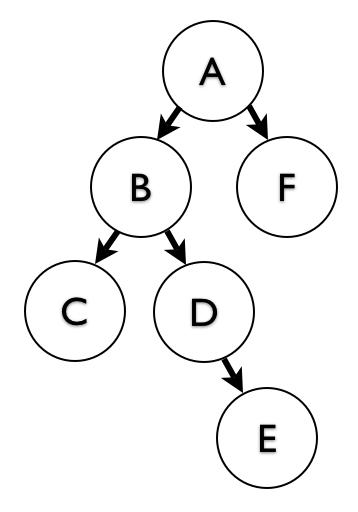
INSERT INTO TreePaths (ancestor, descendant, length)
SELECT supertree.ancestor, subtree.descendant,
supertree.length+subtree.length+1
FROM TreePaths AS supertree JOIN TreePaths AS subtree
WHERE subtree.ancestor = 'D'
AND supertree.descendant = 'B';
This inserts A-D, B-D, A-E, B-E. We already have D-D, D-E, E-E since we’re moving an existing subtree. See the second illustration for the result.
Basically, for both deleting outdated paths and adding new paths, we can imagine a kind of boundary separating the subtree from the rest of the tree. You’re concerned with changing paths that cross over that boundary. Everything else takes care of itself.
I also wrote about Closure Table in my book, SQL Antipatterns: Avoiding the Pitfalls of Database Programming.






Hi Bill,
I’m actually currently researching how a closure tree will compare to a nested set tree for a reasonably sized tree, which led me to your blog post. You’re right about the solution being non-trivial, and your solution looks fairly similar to the one that you commented on here: http://jdobbie.blogspot.com/2009/07/closure-trees.html . While certainly not revolutionary, moving subtrees wasn’t mentioned in the paper, and I couldn’t find anyone who’d written code for it before me, so a link back would be greatly appreciated.
Thanks,
Jonathan Dobbie
You solved one of my biggest problems in just a couple of minutes reading and modifying the queries respecting my tables. It works perfect in any case (if the element that is moved has children or doesn’t have).
Great article!
Many thanks for sharing the idea!
Thanks for your comments Jonathan and Vihren. I’m glad my article was helpful for you!
hi bill,
first of all thanks a lot for all your articules about closure table.Also for your book. I´m learning quite a lot and i have started to use it.However after a couple of weeks coding i have crossed with changes in the design of my data structure. Now we are not going to use a tree but a graph.
I have been reading some info about how to implement graphs in relational DBs, like this one that use mix of adjacent list with helper tables: http://www.oreillynet.com/pub/a/network/2002/11/27/bioconf.html
I have been doing some changes in our closure table design to make it behave like a graph but still i dont get the full relationship to represent a graph with a closure table. Can you point me out to read some info about it,please?
i will really appreciate any help in this particular moment since i would not like to get rid of all the work i have done to use closure table model in our project.
many thanks
Hi Bill,
I’m considering using a closure table to represent a hierarchical model allowing for multiple parents (say E as descendant of D as well as C in your last diagram).
There is however a problem I’ve hit which is moving or deleting a node that is present in two branches of the tree. As an example, let’s say we have a tree similar to the one in your last illustration, but with an extra E node below C: A-B, B-C, C-E, B-D, D-E, A-F (just the immediate connections), and we want to delete the node E descending from D (D-E). In this case we cannot delete the connections to all the other ancestors of E because those connections would still be valid for the node E descending from C. How can I implement a check to make sure we delete A-E, B-E, E-E if and only if they’re the last remaining links to E? Have you already worked on this problem?.
Thanks,
Ricardo Correa
Hi Ricardo,
What you’re describing is a more general-case of a directed acyclic graph (http://en.wikipedia.org/wiki/Directed_acyclic_graph), which is a superset of trees. Working with graphs gets a lot more complicated than working with trees, as you’ve found out. I haven’t tested the Closure Table techniques with DAG structures, since these are used less commonly than trees.
I’m still working on puzzles like how to select two branches independently or the problem you have, which is how to delete one link without deleting all the ancestors’ links if there’s another branch.
It might be more clear to use the Path Enumeration design for your purposes.
I’ve seen only one book that investigates methods of using SQL to work with DAGs: “SQL Design Patterns” by Vadim Tropashko.
http://www.amazon.com/SQL-Design-Patterns-Programming-In-Focus/dp/0977671542/
Hi Bill,
I’m using the closure table hierarchy to store regions in a database using MySQL and I’m wondering how can I create a unordered list with indentation (for each level) with the datas. I know the level of each branch (with the length column) but they are different for each and can be more or less in the future. How can reordered the receive data correctly to do so ? I saw the article with the concatenate path of each entry but the order is not what I need to put it in html. With the tree traversal, it is easy to do so because you’re “walking the path”.
I’m using MySQL, PHP or Coldfusion (I have to do it in both languages so if you have any exemple in one of them) so maybe a query to reorder datas and then put it in an array or structure to loop over…
Thanks, Annie.
I succeed to get my query in correct order but I want to order each level (or path length) by name (because it is country and regions, etc.)
I used this query :
http://stackoverflow.com/questions/8252323/mysql-closure-table-hierarchical-database-how-to-pull-information-out-in-the-c
And I also used the tree traversal way to display my unordered list.
Thanks, Annie.
Annie, the example you link to shows sorting by a ‘breadcrumbs’ string formed by concatenating the id of a given node’s ancestors. To support a user-defined sibling order, you would have to create a ‘breadcrumbs’ string by concatenating some other labels, e.g. name in your case. You should store the name outside the closure table. And you should pad each name to a fixed-length string.
Thanks for the answer! I’m not sure how to do this though to make sure each level of, in my case, regions is in alphabetical order. I tried several things but it was never in the correct order. Here is my query :
SELECT *, GROUP_CONCAT(crumbs.ancestor ORDER BY crumbs.level DESC) AS breadcrumbs
FROM region__region RR
INNER JOIN region__tree RTR
ON RTR.descendant = RR.region_id
INNER JOIN region__tree crumbs
ON crumbs.descendant = RTR.descendant
WHERE RTR.ancestor = 1 AND RTR.level > 0
GROUP BY RR.region_id
ORDER BY breadcrumbs ASC
And I list my regions with this code (in Coldfusion):
#RepeatString(”, currDepth-level)#
#regionName#
#RepeatString(”, currDepth-1)#
Thank you for your help! Keep up the good work, you’re very interesting to read! I would like to attend one of your conference but a bit far from where I live in Canada.
#RepeatString(”, currDepth-level)#
#regionName#
#RepeatString(”, currDepth-1)#
Annie, if you want to sort by your regionName (which I assume is in RR), make breadcrumbs from that instead of the numeric ancestor id.
SELECT *, GROUP_CONCAT(RRcrumbs.regionName ORDER BY crumbs.level DESC) AS breadcrumbs
FROM region__region RR
INNER JOIN region__tree RTR
ON RTR.descendant = RR.region_id
INNER JOIN region__tree crumbs
ON crumbs.descendant = RTR.descendant
INNER JOIN region__region RRcrumbs
ON crumbs.ancestor = RRcrumbs.region_id
WHERE RTR.ancestor = 1 AND RTR.level > 0
GROUP BY RR.region_id
ORDER BY breadcrumbs ASC
You may need to use a SEPARATOR character that doesn’t occur in any regionName, and you may need to use LPAD() to make sure the regionName string is of fixed length, or you could get the wrong sort order.
Thank you! Working pretty well now!
Hi Bill,
I just try to write a reusable Django app named “django-ct”. Your book and this blog post has helped me to create the specification. Is that what I have written in your spirit?
Please take a look: https://django-ct.readthedocs.org/
> It can be easier with the Adjacency List design,
> but in that design you don’t have a convenient way to query for all nodes of a tree
It is very easy using recursive queries which are supported by nearly all DBMS nowadays – MySQL and SQLite being the only ones not to.
Hi Hans,
Yes, you’re right, SQL-99 defines a “common table expression” syntax, and many other RDBMS implementations support this.
AFAIK, Oracle 11g, Microsoft SQL Server 2005, IBM DB2 v7.2, PostgreSQL 8.4, and the H2 database for Java support recursive CTE syntax.
MySQL does not support it in current versions, and this has been a long-standing feature request:
“SQL-99 Derived table WITH clause (CTE)” http://bugs.mysql.com/bug.php?id=16244 (Jan 2006)
CTE and recursive CTE features have also been requested by these other bugs:
http://bugs.mysql.com/bug.php?id=20712 (Jun 2006)
http://bugs.mysql.com/bug.php?id=21893 (Aug 2006)
http://bugs.mysql.com/bug.php?id=23156 (Oct 2006)
http://bugs.mysql.com/bug.php?id=26251 (Feb 2007)
http://bugs.mysql.com/bug.php?id=48610 (Nov 2009)
http://bugs.mysql.com/bug.php?id=60940 (Apr 2011)
Unfortunately, I don’t see any matching worklog tasks at http://dev.mysql.com/worklog/, so we have no expectation that CTE’s or recursive CTE’s will be implemented in MySQL any time soon.
Hi Bill,
I see you only defining the primary key over (ancestor, descendant). However, there are many accesses based on descendant. Since this table will also potentially be very long, don’t we create a KEY on descendant as well?
Hi Ethan,
Yes indeed, depending on the queries we use, the closure table may benefit from additional indexes. I was trying to focus on the logic required for the query, since that’s complex enough for one blog post. 🙂
Bill,
Thank you for taking the time to write about this. The whole concept of a closure table and its implementation in MySQL is brilliant – it has saved me so much time and has allowed me to do things I would have otherwise not have been able to do.
Thanks so much!!
Awesome post,
I just recently found out about closure table through your online slides and other websites.
I’m using SQLite on IOS and as an exercise to learn more about how closure tables work, started to convert some legacy code.
While doing the conversion I ran into precisely the problem of moving an entire sub branch. Luckily I found this blog which has the answer. Only problem is that I am trying to use the example mySQL code that you provided in the blog but it doesn’t seem to work for SQLite 3.
What would be needed in order to get this example working for SQLite 3.
Cheers.
Tim,
are you aware that SQLite now also supports recursive queries?
http://sqlite.org/lang_with.html
As it turns out, the first general Query worked perfectly, forgot to mention that I’m also new to SQLite :
DELETE FROM TreePaths
WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = ‘D’)
AND ancestor NOT IN (SELECT descendant FROM TreePaths WHERE ancestor = ‘D’);
1. As Ethan pointed out earlier that indexing could help with optimizing this table for performance. I’m curious how to setup the table with indexes so that it could be used in a real practical situation without being too sluggish.
Cheers.
Hans, your correct, problem is that even SQLite 3 on IOS 7 is at version 3.7 something. Not yet up to the 3.8.3 that supports recursion
Oops, spoke too soon.
Actually, the SQLite mgr that I am using to test with is using 3.8.4 so the query above might not work on 3.7.1, so have to setup an old version of SQLite to test with to see if it still works.
Happy to report back that the two statements below work great on SQLite version 3.7.1:
DELETE FROM TreePaths
WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = ‘D’)
AND ancestor NOT IN (SELECT descendant FROM TreePaths WHERE ancestor = ‘D’);
INSERT INTO TreePaths (ancestor, descendant, length)
SELECT supertree.ancestor, subtree.descendant,
supertree.length+subtree.length+1
FROM TreePaths AS supertree JOIN TreePaths AS subtree
WHERE subtree.ancestor = ‘D’
AND supertree.descendant = ‘B’;
Was wondering if someone could provide some ideas for the following situation:
1. Closure Table that knows about the order of the children and can insert between the elements.
For example, in the situation below, How to Insert A1 in between B1 and B2 ? ATM , the closure table only knows about the length but not about how the children are ordered with respect to one another.
A —
A1
A2
B —
B1
B2
Hi Tim, none of the solutions for representing hierarchical data include any notion of sibling order by default.
Sorting by sibling order came up in this StackOverflow.com post I answered some time ago:
http://stackoverflow.com/questions/14069674/sorting-a-subtree-in-a-closure-table-hierarchical-data-structure/14074310#14074310
Thanks Bill for the link.
I tried many times to get the example in the posting to work on SQLite.
I duplicated the tables and data for both tables.
1. Tried running this code
SELECT c2.*, cc2.ancestor AS
_parentFROM category AS c1
JOIN category_closure AS cc1 ON (cc1.ancestor = c1.id)
JOIN category AS c2 ON (cc1.descendant = c2.id)
LEFT OUTER JOIN category_closure AS cc2 ON (cc2.descendant = c2.id AND cc2.depth = 1)
WHERE c1.id = 1 AND c1.active = 1
ORDER BY cc1.depth
— and got:
id name active _parent
1 Cat 1 1 NULL
3 Cat 1.1 1 NULL
6 Cat 1.2 1 NULL
7 Cat 1.1.2 1 3
4 Cat 1.1.1 1 NULL
—–
Then I tried running your code:
SELECT c2.*, cc2.ancestor AS
_parent,GROUP_CONCAT(breadcrumb.ancestor ORDER BY breadcrumb.depth DESC) AS breadcrumbs
FROM category AS c1
JOIN category_closure AS cc1 ON (cc1.ancestor = c1.id)
JOIN category AS c2 ON (cc1.descendant = c2.id)
LEFT OUTER JOIN category_closure AS cc2 ON (cc2.descendant = c2.id AND cc2.depth = 1)
JOIN category_closure AS breadcrumb ON (cc1.descendant = breadcrumb.descendant)
WHERE c1.id = 1/*__ROOT__*/ AND c1.active = 1
GROUP BY cc1.descendant
ORDER BY breadcrumbs;
— I got —–
23:54:33 Kernel error: near “ORDER”: syntax error
This is with SQLite 3.8.4
I took out the “ORDER BY breadcrumb.depth DESC” and getting the same result as in the posting:
Question: What is the implication of taking out this ORDER BY clause. Will it break something else in the future? Why doesn’t SQLite support this ORDER BY clause?
Result:
id | name | active | _parent | breadcrumbs |
+—-+————+——–+———+————-+
| 1 | Cat 1 | 1 | NULL | 1 |
| 3 | Cat 1.1 | 1 | 1 | 1,3 |
| 4 | Cat 1.1.1 | 1 | 3 | 1,3,4 |
| 7 | Cat 1.1.2 | 1 | 3 | 1,3,7 |
| 6 | Cat 1.2 | 1 | 1 | 1,6
—- Working SQLite version ————-
SELECT c2.*, cc2.ancestor AS
_parent,GROUP_CONCAT(breadcrumb.ancestor ) AS breadcrumbs
FROM category AS c1
JOIN category_closure AS cc1 ON (cc1.ancestor = c1.id)
JOIN category AS c2 ON (cc1.descendant = c2.id)
LEFT OUTER JOIN category_closure AS cc2 ON (cc2.descendant = c2.id AND cc2.depth = 1)
JOIN category_closure AS breadcrumb ON (cc1.descendant = breadcrumb.descendant)
WHERE c1.id = 1/*__ROOT__*/ AND c1.active = 1
GROUP BY cc1.descendant
ORDER BY breadcrumbs;
Tim, GROUP_CONCAT() is not a standard SQL function, and SQLite is not obligated to support it in the same way that MySQL implements it. SQLite seems to have chosen to implement only a subset of the functionality of GROUP_CONCAT().
The implication of removing that clause is that it’s up to SQLite what order to put the id’s in the breadcrumbs string. There’s no guarantee that the string will be formed in the same way every time, and even if it is, there’s no guarantee it’ll operate the same in a future version of SQLite.
The solution I presented in that StackOverflow answer was specifically for MySQL. For SQLite, you should consider using a different solution with a recursive CTE query, as documented here: http://www.sqlite.org/lang_with.html#recursivecte
Thanks Bill for explanation. It makes perfect sense.
I would really love to use the recursive approach, only thing is that I’m using mobile and currently only SQLite 3.7 is supported. This means no recursion. Your solution would have been perfect if SQLite supported the GROUP_CONCAT(). Would it be possible possible to construct a query to work without recursion and a limited GROUP_CONCAT.
I found this blog that explains how to work around SQLite’s GROUP_CONCAT().
http://www.vertabelo.com/blog/group-concat
Their solution is:
However, you cannot specify the order using SQLite’s group_concat function. To get the order, you have to use a subquery:
select parent_name, group_concat(child_name)
from
(select parent_name, child_name from children order by child_name)
group by parent_name;
Would it be possible to somehow integrate this work around with your original solution ? I tried but could not get it to work because my knowledge of SQL is not so deep.
Hi,
Is it possible to move all child nodes to the other node? Not the node, but only its children.
I recently had a task to find someone’s name within a large hierarchical set. For example, if I was a great great great grandparent of a user named ‘Bob’, and I wanted to find all the Bob’s within my tree, but I didn’t want to list Bobs in other’s tree this is what I did.
Each user had a hierarchy assigned by user id.
IF my user id was 23, and Bob’s user id was 3442
Bob’s hierarchy was 3442,2994,2401,1993,599,23
There was another user within my tree also named Bob, his hierarchy looked like this:
1443,889,599,23
There was a third Bob in the world of Bobs, his hierarchy looked like this:
9423,4232,3322,2223,2
This means the third Bob was not my decendent
I wanted to find the first two Bob’s by name, but not the third.
########### CREATE PROCEDURES TO LOAD ##############################
DROP PROCEDURE IF EXISTS p_parent;
DELIMITER $$
CREATE PROCEDURE p_parent(IN in_user INT,OUT out_parent INT)
BEGIN
SELECT parent_id INTO out_parent FROM users WHERE id = in_user AND id != user_id AND user_id !=0;
END
$$
DELIMITER ;
DROP PROCEDURE IF EXISTS p_hierarchy;
DELIMITER $$
CREATE PROCEDURE p_hierachy(IN in_user INT, OUT out_hierachy VARCHAR(2000))
BEGIN
DECLARE v_UPS varchar(2000) DEFAULT in_presenter;
DECLARE v_UP1 varchar(2000);
DECLARE done INT DEFAULT FALSE;
call p_parent(in_user,@v_id);
SET v_UP1 = @v_id;
SET v_UPS = CONCAT(v_UPS,’,’,COALESCE(@v_id,”));
WHILE @v_id IS NOT NULL DO
call p_parent(v_UP1,@v_id);
SET v_UP1 = @v_id;
SET v_UPS = CONCAT(v_UPS,’,’,COALESCE(@v_id,”));
END WHILE;
SET out_hierachy= v_UPS;
END
$$
DELIMITER ;
DROP FUNCTION IF EXISTS f_get_hierarcy;
DELIMITER $$
CREATE FUNCTION f_get_hierarchy(id INT)
RETURNS VARCHAR(2000)
BEGIN
DECLARE MyResult VARCHAR(1000);
CALL p_hierachy(id, MyResult);
RETURN MyResult;
END$$
DELIMITER ;
###################################################################
## CREATE STORAGE TABLE #############################
CREATE TABLE
user_hierarchy(user_idint(11) NOT NULL,hierarchyvarchar(2000) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,PRIMARY KEY (
user_id),KEY
hierarchy(hierarchy(255))) ENGINE=InnoDB;
### LOAD TABLE ####################################
REPLACE INTO user_hierachy SELECT id, f_get_hierarchy(id) FROM
users;##### FIND NAME IN YOUR TREE OF Users ############################
SELECT * FROM
usersuWHERE
nameLIKE ‘Bob’AND FIND_IN_SET(2,u.hierarchy);
##### FIND NAME IN YOUR TREE OF Users ############################
SELECT * FROM
users u
WHERE name LIKE ‘Bob’
AND FIND_IN_SET(23,u.hierarchy);
Hello,
Any idea why the following request doesn’t work on PostgreSQL ?
INSERT INTO TreePaths (ancestor, descendant, length)
SELECT supertree.ancestor, subtree.descendant,
supertree.length+subtree.length+1
FROM TreePaths AS supertree JOIN TreePaths AS subtree
WHERE subtree.ancestor = ‘D’
AND supertree.descendant = ‘B’;
ERROR: syntax error at or near “WHERE”
LIGNE 1 : …s AS supertree JOIN TreePaths AS subtree WHERE subt…
I know that PostgreSQL supports recursive CTE but my application has to handle both MySQL and PostgreSQL … 🙁
Emmanuel, standard SQL JOIN requires an “ON” clause for the join condition. MySQL has permissive syntax that allows the join condition to be optional, but PostgreSQL requires it.
If you want a cross join with no condition, you can use CROSS JOIN, which is supported by both MySQL and PostgreSQL.
See http://www.postgresql.org/docs/9.3/static/queries-table-expressions.html#QUERIES-FROM
Awesome ! With the CROSS JOIN it works like a charm 🙂
Thanks a lot Bill !
I want to thank you for sharing us this one.
But to add, I was testing the detach node sub-tree query using what you have provided:
DELETE a FROM TreePaths AS a
JOIN TreePaths AS d ON a.descendant = d.descendant
LEFT JOIN TreePaths AS x
ON x.ancestor = d.ancestor AND x.descendant = a.ancestor
WHERE d.ancestor = ‘D’ AND x.ancestor IS NULL;
and it was giving me some unexpected results when I’m reattaching the sub-tree back. Some path are removed.
I was checking if there is a workaround on using the original query in MySQL:
DELETE FROM TreePaths
WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = ‘D’)
AND ancestor NOT IN (SELECT descendant FROM TreePaths WHERE ancestor = ‘D’);
The query above doesn’t work in MySQL but I’ve seen a workaround to do just exactly like that.
http://stackoverflow.com/questions/4471277/mysql-delete-from-with-subquery-as-condition (not the accepted answer though — but the one with the highest votes)
DELETE t FROM TreePaths t
WHERE id IN
(SELECT id FROM
(SELECT id FROM TreePaths
WHERE
descendant IN (
SELECT descendant
FROM closure_table
WHERE ancestor = ‘D’
) AND
ancestor NOT IN (
SELECT descendant
FROM TreePaths
WHERE ancestor = ‘D’
)) as group
);
That query above gives you the same result as the original query you intend to use. It detaches the sub-tree and preserves its structure.
I hope this helps.
Thanks again.
Hi Bill. Thanks a lot for all the explanation on closure tables. I find it great! However, I’ve been having the need to use NoSQL (mongo) to store data. Would you have any recommendations for that? I know they have some documentation here http://docs.mongodb.org/manual/tutorial/model-tree-structures/ but wonder how it compares in terms of performance. I am not sure storing the whole hierarchy path to be the most elegant way of doing that, and don’t know how to compare it to the Closure Table in terms of performance.
Hi ChristianB,
The way you store data doesn’t have performance — queries have performance. So it depends on what type of queries you want to run on the tree-oriented data. Do you want to fetch a whole tree starting from the root with all its descendants? If so, I’d suggest storing a document with nested object references. Do you want to fetch a lower node with its chain of ancestors? If so, I’d suggest storing the materialized path of ancestors.
Modeling data for MongoDB, like many other NoSQL databases, is more or less the same exercise as modeling denormalized data in an SQL database. You can store the data optimally for certain queries, but you have to identify which queries you want to run, and then decide how you can store the data to serve those queries most efficiently.
Hello Mr. Karwin,
in another blog – http://karwin.blogspot.pt/2010/03/rendering-trees-with-closure-tables.html – you used group_concat to “draw” the all the paths of a tree.
how could i change this to work with ms sql ?
I wanted to better understand the portion of the sub-tree relocation where the ancestry is truncated into a stand-alone tree, so I tried to remake it as I understood it, and got this instead:
SELECT X.*
FROM
toolbox.closureAS X #These will be entries with ancestors above THIS but descendants at/below THISINNER JOIN
toolbox.closureAS A #These will be links in which THIS is the descendantON A.ancestor=X.ancestor
INNER JOIN
toolbox.closureAS D #These will be links in which THIS is the ancestorON D.descendant=X.descendant
WHERE A.descendant=@this AND D.ancestor=@this AND X.ancestor != @this;
On my limited testing, on MySQL 5.6, it seems to get the same set. Will my query work correctly?
If so, other than the long WHERE clause, is there a disadvantage to what I came up with? I noticed that mine is dependent on range matching. Yours seems to have a very stable explain plan, whereas mine changes its plan a few times as I add more entries.
This is my setup:
DROP TABLE IF EXISTS
toolbox.closure;CREATE TABLE
toolbox.closure(ancestorINT UNSIGNED NOT NULL,descendantINT UNSIGNED NOT NULL,PRIMARY KEY (
ancestor,descendant));DROP TABLE IF EXISTS
toolbox.thetable;CREATE TABLE
toolbox.thetable(idINT UNSIGNED NOT NULL AUTO_INCREMENT,PRIMARY KEY (
id));INSERT INTO
toolbox.thetableVALUES (1),(2),(3),(4),(5),(6),(7),(8),(9);#Insert this tree
INSERT INTO
toolbox.closureVALUES(1,1), #1 is root of tree
(2,2), (1,2), #2 is child of 1
(3,3), (1,3),(2,3), #3 is child of 2
(4,4), (1,4),(2,4),(3,4), #4 is child of 3
(5,5), (1,5),(2,5),(3,5),(4,5), #5 is child of 4
(6,6), (1,6),(2,6),(3,6), #6 is child of 3
(7,7), (1,7),(2,7),(3,7),(6,7), #7 is child of 6
(8,8), (8,2),(8,1), #8 is a child of 2
(9,9), (9,8),(9,2),(9,1) #9 is a child of 8
;
#Lets make more
INSERT INTO
toolbox.thetableSELECT id+10 FROMtoolbox.thetable;INSERT INTO
toolbox.thetableSELECT id+20 FROMtoolbox.thetable;INSERT INTO
toolbox.thetableSELECT id+40 FROMtoolbox.thetable;INSERT INTO
toolbox.thetableSELECT id+80 FROMtoolbox.thetable;INSERT INTO
toolbox.closureSELECT ancestor+10, descendant+10 FROMtoolbox.closure;INSERT INTO
toolbox.closureSELECT ancestor+20, descendant+20 FROMtoolbox.closure;INSERT INTO
toolbox.closureSELECT ancestor+40, descendant+40 FROMtoolbox.closure;INSERT INTO
toolbox.closureSELECT ancestor+80, descendant+80 FROMtoolbox.closure;SET @this=3;
#Get the hunk of links to remove if making branch into a new tree at 3
SELECT X.*
FROM
toolbox.closureAS X #These are entries with ancestors above THIS but descendants at/below THISINNER JOIN
toolbox.closureAS A #These will be links in which THIS is the descendantON A.ancestor=X.ancestor
INNER JOIN
toolbox.closureAS D #These will be links in which THIS is the ancestorON D.descendant=X.descendant
WHERE A.descendant=@this AND D.ancestor=@this AND X.ancestor != @this;
I meant to also include in the setup an index on descendant in the closure table (which I think is implied in the pattern). In my testing I had it foreign keyed with one, but didn’t want a long comment to be longer :-).
Hello, has anyone seen the closure table concept implemented using JPA / Hibernate? I am relatively new to Hibernate, but its a requirement for the project I am working on.
Really helpful article, thanks Bill!
Those who write: “Wow, this is cool …” Did you really read article???
What is the relationship of the C-D or C-E, it’s funny.
Thanks for the article – my main question re:closure tables is “how do you build one from a table with a parentId column?” I am using DB2 and it does not support CTE’s w/ON clauses (it seems). I’ve done a lot of searching and most articles only talk about maintenance of the closure table (useful for sure), but building one from an existing table is also tricky. 🙂
To answer my own question … 🙂 I found a workable start (for DB2) here http://flylib.com/books/en/4.64.1.23/1/
WITH CT (parentId, childId, depth, name) AS (
SELECT ROOT.parentId, ROOT.id, 0, ROOT.name
FROM Organization ROOT
WHERE ROOT.parentId is NULL
UNION ALL
SELECT CHILD.parentId, CHILD.id, PARENT.depth+1 as depth, CHILD.name
FROM CT PARENT, Organization CHILD
WHERE PARENT.childId = CHILD.parentId
) SELECT DISTINCT parentId, childId, depth, name
FROM CT
ORDER BY depth, parentId, childId;