

Memcache access for MySQL Cluster (or NDBCluster) provides faster access to the data because it avoids the SQL parsing overhead for simple lookups – which is a great feature. But what happens if I try to get multiple records via memcache API (multi-GET) and via SQL (SELECT with IN())? I’ve encountered this a few times now, so I decided to blog about it. I did a very simple benchmark with the following script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | #!/bin/bash mysql_server="192.168.56.75" mc_server="192.168.56.75" mysql_cmd="mysql -h${mysql_server} --silent --silent" mysql_schema="percona" mysql_table="memcache_t" mc_port=11211 mc_prefix="mt:" function populate_data () { nrec=$1 $mysql_cmd -e "delete from ${mysql_table};" $mysql_schema > /dev/null 2>&1 for rec in `seq 1 $nrec` do $mysql_cmd -e "insert into ${mysql_table} values ($rec, repeat('a',10), 0, 0);" $mysql_schema > /dev/null 2>&1 done } function mget_via_sql() { nrec=$1 in_list='' for rec in `seq 1 $nrec` do in_list="${in_list}${rec}" if [ $rec -lt $nrec ] then in_list="${in_list}," fi done start_time=`date +%s%N` $mysql_cmd -e "select id,value from ${mysql_table} where id in (${in_list});" ${mysql_schema} > /dev/null 2>&1 stop_time=`date +%s%N` time_ms=`echo "scale=3; $[ $stop_time - $start_time ] /1000 /1000" | bc -l` echo -n "${time_ms} " } function mget_via_mc() { nrec=$1 get_str='' for rec in `seq 1 $nrec` do get_str="${get_str} ${mc_prefix}${rec}" done start_time=`date +%s%N` echo "get ${get_str}" | nc $mc_server $mc_port > /dev/null 2>&1 stop_time=`date +%s%N` time_ms=`echo "scale=3; $[ $stop_time - $start_time ] /1000 /1000" | bc -l` echo -n "${time_ms} " } function print_header() { echo "records mget_via_sql mget_via_mc" } print_header populate_data $records sleep 10 for records in `seq 1 50` do echo -n "$records " mget_via_sql $records mget_via_mc $records echo done |
The test table looked like the following.
1 2 3 4 5 6 7 8 9 10 11 | mysql> show create table percona.memcache_tG *************************** 1. row *************************** Table: memcache_t Create Table: CREATE TABLE `memcache_t` ( `id` int(11) NOT NULL DEFAULT '0', `value` varchar(20) DEFAULT NULL, `flags` int(11) DEFAULT NULL, `cas_value` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING HASH ) ENGINE=ndbcluster DEFAULT CHARSET=latin1 1 row in set (0.00 sec) |
The definitions for memcache access in the ndbmemcache schema were the following.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | mysql> select * from key_prefixes where key_prefix='mt:'; +----------------+------------+------------+----------+------------+ | server_role_id | key_prefix | cluster_id | policy | container | +----------------+------------+------------+----------+------------+ | 0 | mt: | 0 | ndb-only | memcache_t | +----------------+------------+------------+----------+------------+ 1 row in set (0.00 sec) mysql> select * from containers where name='memcache_t'; +------------+-----------+------------+-------------+---------------+-------+------------------+------------+--------------------+--------------------+ | name | db_schema | db_table | key_columns | value_columns | flags | increment_column | cas_column | expire_time_column | large_values_table | +------------+-----------+------------+-------------+---------------+-------+------------------+------------+--------------------+--------------------+ | memcache_t | percona | memcache_t | id | value | flags | NULL | cas_value | NULL | NULL | +------------+-----------+------------+-------------+---------------+-------+------------------+------------+--------------------+--------------------+ 1 row in set (0.00 sec) mysql> select * from memcache_server_roles where role_id=1; +-----------+---------+---------+---------------------+ | role_name | role_id | max_tps | update_timestamp | +-----------+---------+---------+---------------------+ | db-only | 1 | 1000000 | 2013-04-07 21:59:02 | +-----------+---------+---------+---------------------+ 1 row in set (0.00 sec) |
I had the following results – the variance is there because I did this benchmark on a cluster running in virtualbox on my workstation, but the trend shows clearly.
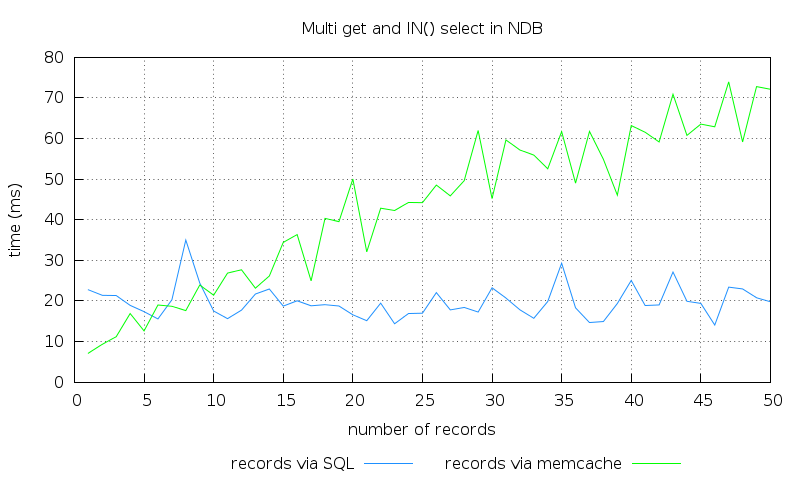
The surprising result is that if we fetch 1 or a few records, the memcached protocol access is indeed faster. But the more records we fetch, the speed of the SQL won’t change too much, while the time required to perform the memcache multi-get is proportional with the number of record fetched. This result actually makes sense if we dig deeper. The memcache access can’t use batching, because of the way multi-get is implemented in memcached itself. On the server side, there is simply no multi-get command. The get commands are done in a loop, one by one. With a regular memcache server, one multi-get command will need one network roundtrip between the client and the server. In NDB’s case, for each key access, a roundtrip still has to be made to the storage node, and this overhead is not present in the SQL node’s case (the api and the storage nodes were running on different virtual macines). If we are using the memcache API nodes with caching, the situations gets somewhat better if the key we are looking for is in memcached’s memory (the network roundtrip can be skipped in this case).
Does this mean that memcache API is bad and unusable? I don’t think so. Most workloads, which are in need of the memcache protocol access, will most likely use it for getting one record at a time. It shines there compared to SQL (response time is less than half). This example shows that for the “Which is faster?” question, the correct answer is still, “It depends on the workload.” For most cases, anyhow.






There is some potential for better batching. In the memcached binary protocol (but not the ASCII protocol) you can pipeline GETKQ requests followed by a final GETK. With a small change in the NDB Engine, we could batch all of these into one transaction, and see performance similar to mysqld. Unfortunately it would require a much bigger change to the open source core of memcached 1.6, so it would be interesting to understand the use cases for batching and to know how much benefit people could get from this work.