

If we have InnoDB pages there are two ways to learn how many records they contain:
- PAGE_N_RECS field in the page header
- Count records while walking over the list of records from infimum to supremum
In some previous revision of the recovery tool a short summary was added to a dump which is produced by the constraints_parser.
But if a page is lost and page_parser hasn’t found it, all records from this page are lost. In other words per-page recovery statistics gives us little idea about whether or not a recovered table is complete.
To cover this flaw a new tool index_check is introduced in the revision 80
As you might know InnoDB stores a table in a clustered index called PRIMARY.
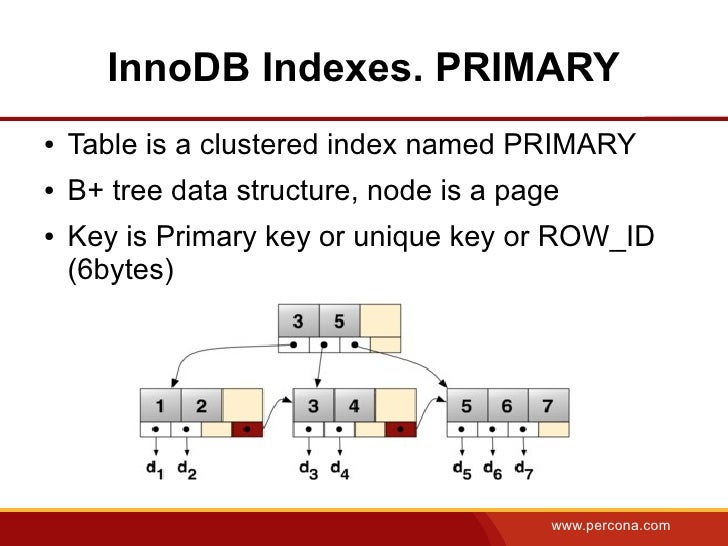
The PRIMARY index is a B+tree structure. It has a nice feature that all leaf nodes have pointers to a next leaf node, so following the pointers we can read whole index in the primary key order. InnoDB extends the structure and stores also a pointer to the previous node. The previous node of the head is NULL as well as the next node of the tail.
Based on this knowledge we can check if we have all elements of the list. If we can get from any InnoDB page to the beginning and the end of the list then our set of pages is complete.
This is exactly what index_chk does – it reads files from a directory with InnoDB pages (that is produced by page_parser) and tries to walk over the list of pages back and forth.
Let’s review an example. I took some corrupt InnoDB tablespace and split it with a page_parser:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # ./page_parser -f /var/lib/mysql/ibdata1 Opening file: /var/lib/mysql/ibdata1 File information: ID of device containing file: 64512 inode number: 27037954 protection: 100660 (regular file) number of hard links: 1 user ID of owner: 107 group ID of owner: 116 device ID (if special file): 0 blocksize for filesystem I/O: 4096 number of blocks allocated: 86016 time of last access: 1374662334 Wed Jul 24 06:38:54 2013 time of last modification: 1374233938 Fri Jul 19 07:38:58 2013 time of last status change: 1374233938 Fri Jul 19 07:38:58 2013 total size, in bytes: 44040192 (42.000 MiB) Size to process: 44040192 (42.000 MiB) 8.26% done. 2013-07-24 08:39:58 ETA(in 00:00 hours). Processing speed: 3637248 B/sec ... 95.70% done. 2013-07-24 08:40:09 ETA(in 00:00 hours). Processing speed: 4399053 B/sec # |
Now let’s take some index and check if it has all pages:
1 2 3 4 5 6 7 | # ls pages-1374669586/FIL_PAGE_INDEX/0-410/ 00000000-00000145.page 00000000-00000235.page 00000000-00000241.page 00000000-00000247.page 00000000-00000254.page 00000000-00000147.page 00000000-00000236.page 00000000-00000243.page 00000000-00000249.page 00000000-00000255.page 00000000-00000148.page 00000000-00000239.page 00000000-00000244.page 00000000-00000251.page # ./index_chk -f pages-1374669586/FIL_PAGE_INDEX/0-410 Couldn't open file pages-1374669586/FIL_PAGE_INDEX/0-410/00000000-00000140.page # |
Bad news, a page with id 140 is missing!
Indeed the previous page before page#145 is page#140, but it’s missing.
1 2 3 4 | # hexdump -C pages-1374669586/FIL_PAGE_INDEX/0-410/00000000-00000145.page | head -2 00000000 d4 cd 68 41 00 00 00 91 00 00 00 8c ff ff ff ff |..hA............| 00000010 00 00 00 00 2b 6c ea 90 45 bf 00 00 00 00 00 00 |....+l..E.......| # |
For a cheerful ending let’s check an index that has all pages:
1 2 3 4 5 6 | # ls pages-1374669586/FIL_PAGE_INDEX/0-2/* # this is SYS_COLUMNS table pages-1374669586/FIL_PAGE_INDEX/0-2/00000000-00000010.page pages-1374669586/FIL_PAGE_INDEX/0-2/00000000-00002253.page pages-1374669586/FIL_PAGE_INDEX/0-2/00000000-00002244.page # ./index_chk -f pages-1374669586/FIL_PAGE_INDEX/0-2 OK # |
Thus, a table is fully recovered if and only if two conditions are met:
- Command grep “Lost records: YES” table.dump | grep -v “Leaf page: NO” outputs nothing
- ./index_chk -f pages-1374669586/FIL_PAGE_INDEX/<inde_id of=”” my=”” table=””> reports OK




