

Yesterday we announced the GA release of Percona Server 5.6, the latest release of our enhanced, drop-in replacement for MySQL. Percona Server 5.6 is the best free MySQL alternative for demanding applications. Our third major release, Percona Server 5.6 offers all the improvements found in MySQL 5.6 Community Edition plus scalability, availability, backup, and security features some of which are found only in MySQL 5.6 Enterprise Edition.
Percona Server 5.6 comes with:
- General performance improvements
- Extensive diagnostics via TABLE/INDEX/USER STATISTIC and slow query log
- Thread Pool plugin
- Pluggable Authentication Module plugin
- Integration with Percona XtraBackup: “Real” incremental backups and Archive logs backups
- Statement timeouts
- Fully drop-in compatible with MySQL
General performance improvements
MySQL 5.6 by itself comes with a great list of performance fixes, however what we discovered that their focus was on small datasets that fit into memory. In other words, mostly on CPU-bound workloads.
In our research we found that in IO-bound cases there is still room for improvement so we took action:
- Ported good old buffer mutex split from Percona Server 5.5 to Percona Server 5.6. This helps to decrease a contention on buffer pool even further.
- Implemented “priority” mutexes and rw-locks in InnoDB, check https://blueprints.launchpad.net/percona-server/+spec/xtradb-priority-mutex. Free list priority refill now gets priority in obtaining mutexes.
- Implemented “Thread scheduling.” Now it is possible to change priority for InnoDB Cleaner thread. This helps to stabilize performance, as we found that in IO-heavy workloads, the cleaner thread is “starving” and not getting enough CPU time to do its job.
- Implemented new waiting algorithms with exponential wait on the access to shared resources.
- Additional tunings to Page Cleaner thread.
For performance improvements and testing I would like to give credit to Percona engineers Laurynas Biveinis and Alexey Stroganov.
Diagnostics via TABLE/INDEX/USER STATISTIC and slow query log
Even with MySQL 5.6’s rich PERFORMANCE_SCHEMA information, we decided to keep our diagnostics. Why? Because it is very easy to use. Check Domas’ post on this topic.
Integration with Percona XtraBackup: “Real” incremental backups and Archive logs backups
Percona Server comes with following backup features:
- Changed page tracking AKA “Real” incremental backups. Using this feature will avoid full table scans for incremental backups, and information on changed pages is now available in bitmap files.
- Archive Logs. An alternative way to perform incremental backups by copying InnoDB transactional logs and applying them to backup.
These features are unique to Percona Server, and, in combination with Percona XtraBackup, they allow users to achieve greater flexibility in backup schemas.
Statement timeouts
This feature was ported from Twitter’s fork of MySQL and allows users to control execution time of statements.
You are welcome to review what has changed in Percona Server 5.6 in our summary, compare with previous Percona Server releases, or compare with MySQL 5.6.
How do we do QA of Percona Server
For QA testing I want to give credit to Roel Van De Paar and his Random Query Generator extensions specific for new Percona Server features. By using RQG together with a new option combinatorics approach (expect a blog post on this soon), we are confident in the quality of Percona Server.
Also, we found, reported and fixed quite a large number of bugs for upstream MySQL.
Performance results
And of course I want to share benchmark results. What kind of performance gain can we expect with all these performance improvements I explained above?
For tests I took sysbench OLTP read-write workload with pareto distribution. The dataset is 32 tables, 10mln rows each, which totals about ~77GB of data. Our interest is intensive IO-bound workload, so buffer_pool size is 25GB and we ran the load in 250 user threads.
For hardware I used a Cisco UCS 250 server with two Intel(R) Xeon(R) CPU X5670, Ubuntu 12.04.3 LTS as the OS and very high-end PCIe SSD storage (capable of 100,000 IOPS in random 16KB writes).
So let’s compare Percona Server 5.6 and MySQL 5.6 in this workload. The graph shows timeline for 30 mins run with 1 sec resolution.
Throughput (more is better):

95% Response time (less is better):
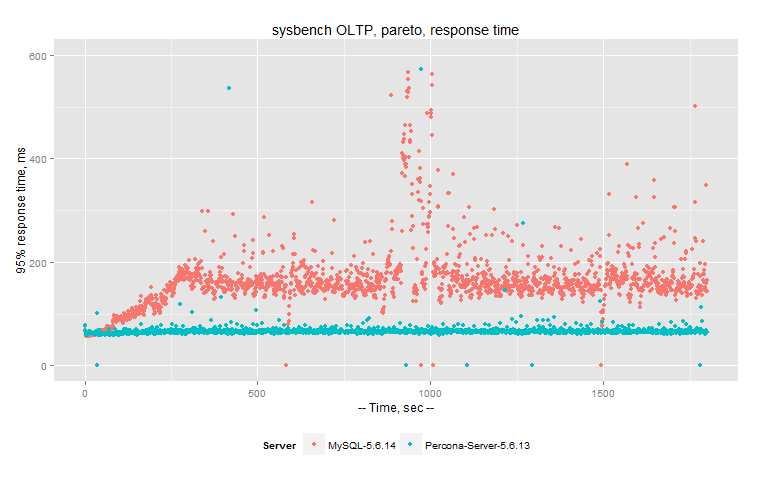
We find that Percona Server 5.6 provides 2x better performance (in both throughput and response time) with much less variance.
This is possible to achieve by decreasing internal contention in InnoDB and prioritizing page cleaner thread and free list refill.
Now let me share configuration files for this run:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | [mysqld] innodb_data_file_path=ibdata1:10M:autoextend innodb_log_files_in_group=2 innodb_log_file_size=2G innodb_buffer_pool_size=25GB innodb_lru_scan_depth=4000 innodb_flush_neighbors=0 innodb_log_buffer_size=256M innodb_io_capacity = 25000 innodb_io_capacity_max= 50000 innodb_flush_log_at_trx_commit = 1 innodb_buffer_pool_instances=15 innodb_file_format = Barracuda innodb_checksum_algorithm = crc32 innodb_file_per_table = true innodb_doublewrite=1 innodb_flush_method=O_DIRECT_NO_FSYNC innodb_purge_threads=4 table_open_cache=15000 open_files_limit=15000 max_connections=15000 innodb_read_io_threads = 8 innodb_write_io_threads = 8 innodb_change_buffering=all loose-innodb_sync_array_size=16 sync_binlog=0 query_cache_type=OFF thread_cache_size=1000 back_log=2000 connect_timeout=15 loose-metadata_locks_hash_instances=256 max_prepared_stmt_count=1048560 loose-performance_schema=0 # --- below is Percona Server Specific --- innodb_sched_priority_cleaner=39 innodb_log_block_size=4096 innodb_adaptive_hash_index_partitions=65 |
And some comments on it:
1. Please note that we are using fully durable settings:
innodb_flush_log_at_trx_commit = 1
innodb_doublewrite=1
innodb_checksum_algorithm = crc32
This is different from the results provided by MySQL, where, to get better numbers, they disable data protection.
2. innodb_checksum_algorithm = crc32. New hardware crc32 checksums actually provide much better performance, and we recommend using it whenever possible (Please note this will have an effect only on new created databases, and not for databases created in previous versions of the server)
3. Percona Server only specific settings:
innodb_sched_priority_cleaner=39 – to give highest priority to page cleaner thread
innodb_log_block_size=4096 – to use 4096 block size for InnoDB logs
innodb_adaptive_hash_index_partitions=65 – to enable partitioning of adaptive hash index, otherwise quite often this is a contention point.
And some variables which are used by default in Percona Server.
innodb_foreground_preflush=exponential_backoff
innodb_empty_free_list_algorithm=backoff
innodb_cleaner_lsn_age_factor=high_checkpoint
As a disclaimer I should mention that I expect the difference between Percona Server 5.6 and MySQL 5.6 performance will grow even wider with a larger dataset, more memory and faster storage.
For a small dataset which fits into memory on low-end servers, Percona Server 5.6 performance will be identical to MySQL 5.6 performance. Credit where credit is due: MySQL did a great job optimizing InnoDB for small datasets in memory.
This characteristics of Percona Server 5.6 are actually very important. With our server you are able to scale your workload by a simple hardware upgrade. By increasing CPU speed, increasing memory or upgrading your storage, you get better performance with Percona Server.
You are welcome to try Percona Server 5.6 yourself and give us your feedback!
What is in the future?
We are not stopping here. Expect new improvements and more features.
- More InnoDB performance improvements. What we have done so far is only the tip of the iceberg and has opened the door for further research
- TokuDB support. We will ship TokuDB in one of the next Percona Server 5.6 releases
- Per query variables. We will add a new scope (in additional to global and session) for MySQL variables: per query. You will be able to change some variable only for one specific query
- Percona XtraDB Cluster 5.6, based on Percona Server 5.6 with all of its improvements, will be available in few months
Should you need any assistance in planning your Percona Server 5.6 upgrade or migration for your company, we’re here to help. Percona has seasoned support and consulting professionals available around the world that are ready for your call. Contact us today.






Great improvements iverall thank you.
Since cluster is not yet released, With this release 5.6 what version of xtradb cluster can be used and will it work without any issues ? Or to use the cluster, do we need to wait for cluster 5.6 release?
Is the standard replication works?
Great improvements iverall thank you.
Since cluster is not yet released, With this release 5.6 what version of xtradb cluster can be used and will it work without any issues ? Or to use the cluster, do we need to wait for cluster 5.6 release?
Is the standard replication works?
Great Results Vadim!
I see there are some micro stalls in Percona Server 5.6 still with small number of samples showing 0 transactions per second. If this is not the data capture glitch there is some work to be done still 🙂
Why was this needed given that the buffer pool is sharded in 5.6 (innodb_buffer_pool_instances)?
>>Ported good old buffer mutex split from Percona Server 5.5 to Percona Server 5.6. This helps to decrease a contention on buffer pool even further.
By increasing the overall mutexes per buffer pool, contention in any instance is reduced an parallelism is increased. For example, if you have an insert heavy workload, the adaptive hash index mutex may be very hot in every instance. By separating this mutex from other mutexes, reads may see increased performance. This is particularly true in PS because the adaptive hash index can be partitioned and each INDEX_ID goes to a partition. So mutex contention is reduced that much further.
Actually, maybe the AHI was a bad example. The biggest advantage is that the flush list and free list and LRU can all be manipulated independently in many cases in each BP instance. This likely has implications for purge and page cleaner threads in particular.
BUT – I haven’t profiled PS 5.6 so this is speculation at some level.
Per query variables – cool stuff coming 🙂
Really impressive work and very welcome news.
Bravo, the stability of the Percona Server 5.6 numbers is very impressive.
This looks great.
Can you also benchmark this vs MariaDB (and possibly MySQL 5.7)? It’d be interesting to see how they stack up.
Peter –
You are right re. further work remaining 🙂
Mark, Justin –
On buffer pool mutex split vs instances. I believe the split comes
before the instances for I/O-bound cases (and instances are perfectly
fine for CPU-bound cases, not much need for split there). One day I
hope to blog about it with some numbers, but here’s a shorter
hand-wavy version:
1) Instances are not used uniformly, split LRU lists mean there is no
global LRU list anymore. Which should mean (here’s the part where
I don’t have numbers), that hotter instances are evicting or
flushing too hot pages, in the end causing more read I/Os.
2) Instances are not used uniformly, doesn’t matter if we have 15 out
of 16 instances with full free lists, if the last instance is
empty and we need a page from it, too bad, flushing/evicting
time. We see this all the time.
3) If the above is correct, then the fewer the instances in I/O-bound
workloads the better. Split mutex should allow to reduce their
number.
4) Splitting the mutex clarifies what’s going on and is a prerequisite
for further work. Right now we don’t have a hot buffer pool mutex
anymore, we have hot LRU and free list mutexes. They are rarely
held together. All the free list mutex contention is in
buf_LRU_get_free_only() taking its pages and in
buf_LRU_block_free_non_file_page() providing its pages, directly
leading to our priority free list refill work. With the unsplit
mutex it’d have been harder to discover this. We could have
implemented a similar fix with the unsplit mutex too, but I
suspect that it would be much less effective, because instead of a
very short free list mutex lock in
buf_LRU_block_free_non_file_page(), we’d have a much longer buffer
pool mutex lock in its caller.
5) Now we also know what’s going on with the LRU list mutex. About
half of its contention is in buf_page_make_young() called from
buf_page_make_young_if_needed() in I/O-bound workloads. (probably
more in CPU-bound workloads, but there my guess it should be
clearly visible with the unsplit mutex too and easily fixable with
just raising the number of instances). This gives some direction
for our future work, and also for specific workloads might suggest
innodb_old_blocks_pct/innodb_old_blocks_time tuning.
6) Mikael Ronstrom’s post from 2010
http://mikaelronstrom.blogspot.com/2010/09/multiple-buffer-pools-in-mysql-55.html
suggests that instances are better than the split because the
number of places where multiple mutexes must be held is high.
There are such places, yes, but I cannot think of any on the hot
code paths. As discussed above, LRU and free list mutexes are
contended separately. Of course the picture is different if your
workload is doing compressed page flush list relocations all the
time. Compressed pages also remind me that we have addressed all
the quality concerns we had with our mutex split patch, thanks to
Roel.
Peter,
Yes, we still have drops to zero in Percona Server, the reason is the bug in upstream, the bug is that “server is idle” detection is broken, and in some random time InnoDB decides that the server is idle, than trying to flush all dirty page, and in this way effectively locks all activities.
Also I would like to point that we are able to detect these stalls because now we use 1 sec resolution in the benchmark report. Before when we used 10 sec resolutions these stall were just smoothed in average calculations. I think 1 sec should become a standard for benchmarks.
Hi.
The troughput graph looks really nice. What tool did you use to generate it?
Looking forward to per query settings. Something, I’d love to see in a different context.
Laurynas,
I wonder on uniformity. If we have buffer pool of say 16GB it will be 1M pages, split to 8 buffer pools we’re looking at 125K pages per buffer pool or so. Unless there is poor hash function in use you should have pretty uniform split of accessed pages to the buffer pools. Are you saying you do not see it ?
Now there are few things which can happen outside of the general hashing issue. For example you can have some page which is a hotspot (ie some hot row in counter table), the other thing the processing of these buffer may be not uniform by threads which are responsible for flushing cleaning etc.
My point is to ensure there is not some mapping bug there if we see more difference between buffer pools than Math would tell us to expect.
Peter,
On uniformity,
As I understand the issue is not in the page distribution – it actually work fine.
The issue is in how pages are flushed.
Say you have 500 dirty pages in each 15 buffer pool instances.
InnoDB asks to flush 750 pages.
So in this case: From buffer pool instance 1 – 500 pages flushed.
From buffer pool instance 2 – 250 pages flushed
the rest buffer pool instances – 0 pages flushed.
As you understand, after you some period of work, the distribution of dirty pages in this case becomes very non-uniform.
Peter –
That’s correct: we do not see uniformity, and again according to Mikael’s original post http://mikaelronstrom.blogspot.com/2010/09/multiple-buffer-pools-in-mysql-55.html, we were not supposed to see it: “First the accesses to the buffer pools is in no way evenly spread out. This is not surprising given that e.g. the root page of an index is a very frequently accessed page.”
But Alexey Stroganov and I spent some time looking into it as well. The current hash function is as simple as it can get. We tried couple of different hash functions, together with some other tweaks such as separate undo tablespaces to spread out space id some more, but we never reached uniformity.
Now that I think about it, innodb-file-per-table=0 perhaps could make things more uniform 🙂
Vadim –
Flushing is spread across the instances uniformly both in Oracle and in our page cleaner. In your example it would ask each instance to flush 500/15 pages. Also, when we added page cleaner timeouts, we added it so the current pass over all instances still completes.
AFAIK the page cleaner thread tries to do this once per second from each buffer pool instance
* flush io_capacity / buffer_pool_instances dirty pages
* flush lru_scan_depth dirty pages from the tail of the LRU
Note that one rate is per instance, the other is not. That has confused me in the past.
A simple change for Percona is to let the page cleaner thread try to run more than once per second, and then configure it to do less work per iteration.
Mark –
Done.
I should be more specific. Our cleaner thread does not attempt to sleep the remaining time until 1 second but rather adapts the sleep time according to total free list length and checkpoint age.
Nice article. I’m also curious about the performance difference between Percona 5.5 and 5.6.
Vadim,
Yes I expect something like what you describe can be happening which is essentially the “bug” which prevents uniform handling of multiple buffer pools
Curious, the documentation states that innodb_adaptive_hash_index_partitions has value ranging from 1-32 for 32-bit and 1-64 on 64-bit systems. What does 65 do?
PaulC,
It is a typo, it should be 64, thanks.
Looks like the engine (5.5.33-rel31.1) does the right thing anyway:
[Warning] option ‘innodb-adaptive-hash-index-partitions’: unsigned value 65 adjusted to 64.
Given the value range here and guessing at what you’re doing in the code is it safe to assume that it’s best to pick powers of 2 as opposed to prime numbers or does it not really matter?
PaulC –
Does not really matter. The value range is historical, there is no inherent max value limitation anymore. The AHI partition assignment is index id mod number of AHI partitions.
On a related note, Stewart Smith will be hosting a webinar on Oct. 16 highlighting the differences between Percona Server 5.6, Percona Server 5.5, and MySQL 5.6. More info and registration here:
https://www.percona.com/resources/mysql-webinars/percona-server-56-enterprise-grade-mysql-outstanding-performance.
It will be recorded and available at that same url afterward.
Jan-
I think Vadim used R (http://cran.r-project.org/index.html) and ggplot2 (http://docs.ggplot2.org/) to make the plots. I highly recommend both! He has also posted about using R and ggplot2 for making his plots on this site before (http://www.mysqlperformanceblog.com/2012/02/23/some-fun-with-r-visualization/).
Just curious as to the types of disks you are using that can withstand the innodb_io_capacity setting of 25K? Great stuff otherwise . . .
The link to https://www.percona.com/doc/percona-server/5.6/performance/xtradb_performance_improvements.html#relative-thread-scheduling-priorities-for-xtradb results in a ‘Page not found’.
@Daniel Nichter
Link has been fixed, thanks for reporting this.
i am Execute a same query Local system only take ka less time 10000000 1.35 sec and same query put a remot database than take a time more 5.35 mines 35 second .. so query take more i/o cycle .. this query use sub query and join ..
any one let solve this problem ……