

This blog, MySQLPerformanceBlog.com, is powered by WordPress, but we never really looked into what kind of queries to MySQL are used by WordPress. So for couple months we ran a Query Analytics (part of Percona Cloud Tools) agent there, and now it is interesting to take a look on queries. Query Analytics uses reports produced by pt-query-digest, but it is quite different as it allows to see trends and dynamics of particular query, in contrast to pt-query-digest, which is just one static report.
Why looking into queries important? I gave an intro in my previous post from this series.
So Query Analytics give the report on the top queries. How to detect which query is “bad”?
One of metrics I am typically looking into is ratio of “Rows examined” to “Rows sent”. In OLTP workload
I expect “Rows sent” to be close to “Rows examined”, because otherwise it means that a query handles a lot of rows (“examined”) which are not used in final result set (“sent”), and it means wasted CPU cycles and even unnecessary IOs if rows are not in memory.
Looking on WordPress queries it does not take long to find one:

This one actually looks quite bad… It examines up to ~186000 rows to return 0 or in the best case 1 row.
The full query text is (and this is available in Query Analytics, you do not need to dig through logs to find it):
SELECT comment_ID FROM wp_comments WHERE comment_post_ID = '154' AND comment_parent = '0' AND comment_approved != 'trash' AND ( comment_author = 'poloralphlauren.redhillrecords' OR comment_author_email = '[email protected]' ) AND comment_content = 'Probabilities are in case you are like the ma spam jorityof people nowadays, you're f lululemonaddictoutletcanadaSale.angelasauceda ighting tooth and nail just looking to keep up together with your existence. Acquiring organized can help you win the fight. Appear to the ugg factors in just abo spam ut every of your spaces (desk, workplace, living room, bed' LIMIT 1;
We can see how execution time of this query changes overtime
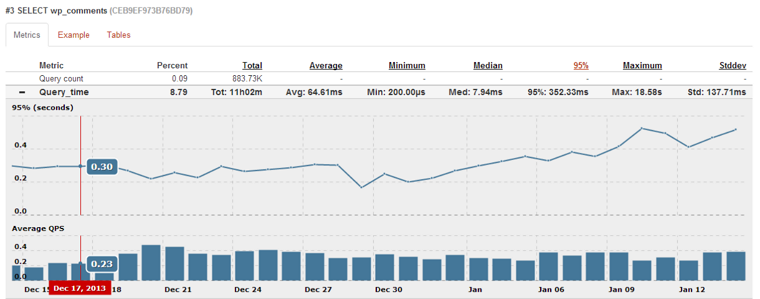
and also how many rows it examines for the last month
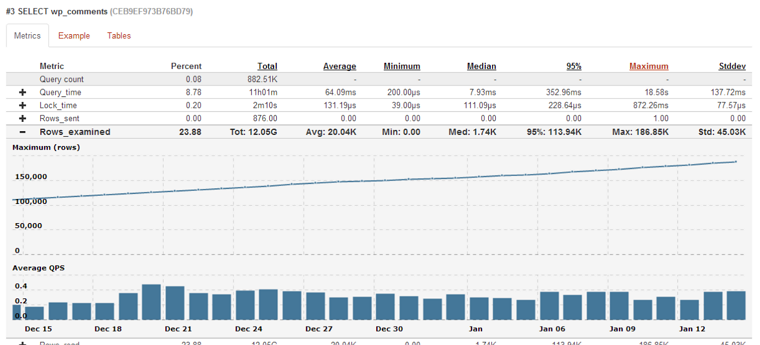
It is clearly an upward trend, and obviously the query does not scale well as there more and more data.
I find these trending graphs very useful and they are available in Query Analytics as we continuously digest and analyze queries. We can see that only for the last month amount of rows this query examines increased from ~130K to ~180K.
So, the obvious question is how to optimize this query?
We look into the explain plan
1 2 3 4 5 | +----+-------------+-------------+------+----------------------------------------------------------+-----------------+---------+-------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------------+------+----------------------------------------------------------+-----------------+---------+-------+--------+-------------+ | 1 | SIMPLE | wp_comments | ref | comment_post_ID,comment_approved_date_gmt,comment_parent | comment_post_ID | 8 | const | 188482 | Using where | +----+-------------+-------------+------+----------------------------------------------------------+-----------------+---------+-------+--------+-------------+ |
and SHOW CREATE TABLE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | CREATE TABLE `wp_comments` ( `comment_ID` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `comment_post_ID` bigint(20) unsigned NOT NULL DEFAULT '0', `comment_author` tinytext NOT NULL, `comment_author_email` varchar(100) NOT NULL DEFAULT '', `comment_author_url` varchar(200) NOT NULL DEFAULT '', `comment_author_IP` varchar(100) NOT NULL DEFAULT '', `comment_date` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', `comment_date_gmt` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', `comment_content` text NOT NULL, `comment_karma` int(11) NOT NULL DEFAULT '0', `comment_approved` varchar(20) NOT NULL DEFAULT '1', `comment_agent` varchar(255) NOT NULL DEFAULT '', `comment_type` varchar(20) NOT NULL DEFAULT '', `comment_parent` bigint(20) unsigned NOT NULL DEFAULT '0', `user_id` bigint(20) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`comment_ID`), KEY `comment_post_ID` (`comment_post_ID`), KEY `comment_approved_date_gmt` (`comment_approved`,`comment_date_gmt`), KEY `comment_date_gmt` (`comment_date_gmt`), KEY `comment_parent` (`comment_parent`) ) |
Obviously WordPress did not design this schema to handle 180000 comments to a single post.
There are several ways to fix it, I will take the easiest way and change the key
KEY comment_post_ID (comment_post_ID)
to
KEY comment_post_ID (comment_post_ID,comment_content(300))
and it changes execution plan to
1 2 3 4 5 | +----+-------------+-------------+------+----------------------------------------------------------------------------------------------------------------+-------------------+---------+-------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------------+------+----------------------------------------------------------------------------------------------------------------+-------------------+---------+-------------+------+-------------+ | 1 | SIMPLE | wp_comments | ref | comment_post_ID,comment_approved_date_gmt,comment_parent | comment_post | 910 | const,const | 1 | Using where | +----+-------------+-------------+------+----------------------------------------------------------------------------------------------------------------+-------------------+---------+-------------+------+-------------+ |
From 186000 rows to 910 rows – that’s quite improvement!
How does it affect execution time? Let’s query run for a while and see again in our trending graph:
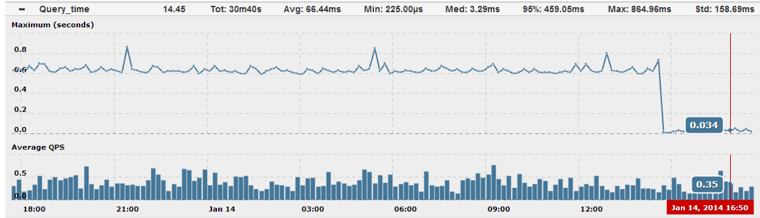
The drop from ~600ms to ~34ms
and for Rows examined:
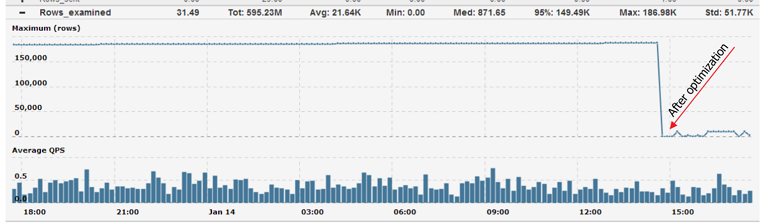
The 2nd query is also not to hard to find, and it is again on wp_comments table
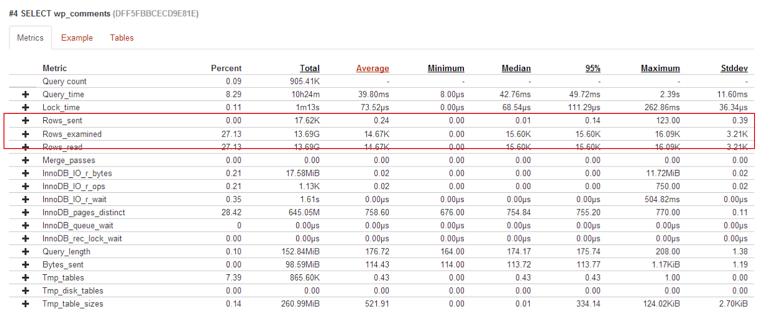
The query examines up to 16K rows, sending only 123 in the best case.
Query text is (this one is from different instance of WordPress, so the table structure is different)
SELECT comment_post_ID FROM wp_comments WHERE LCASE(comment_author_email) = '[email protected]' AND comment_subscribe='Y' AND comment_approved = '1' GROUP BY comment_post_ID
and EXPLAIN for this particular one
1 2 3 4 5 | +----+-------------+-------------+------+---------------------------+---------------------------+---------+-------+------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------------+------+---------------------------+---------------------------+---------+-------+------+----------------------------------------------+ | 1 | SIMPLE | wp_comments | ref | comment_approved_date_gmt | comment_approved_date_gmt | 62 | const | 6411 | Using where; Using temporary; Using filesort | +----+-------------+-------------+------+---------------------------+---------------------------+---------+-------+------+----------------------------------------------+ |
This table structure is
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | CREATE TABLE `wp_comments` ( `comment_ID` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `comment_post_ID` bigint(20) unsigned NOT NULL DEFAULT '0', `comment_author` tinytext NOT NULL, `comment_author_email` varchar(100) NOT NULL DEFAULT '', `comment_author_url` varchar(200) NOT NULL DEFAULT '', `comment_author_IP` varchar(100) NOT NULL DEFAULT '', `comment_date` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', `comment_date_gmt` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', `comment_content` text NOT NULL, `comment_karma` int(11) NOT NULL DEFAULT '0', `comment_approved` varchar(20) NOT NULL DEFAULT '1', `comment_agent` varchar(255) NOT NULL DEFAULT '', `comment_type` varchar(20) NOT NULL DEFAULT '', `comment_parent` bigint(20) unsigned NOT NULL DEFAULT '0', `user_id` bigint(20) unsigned NOT NULL DEFAULT '0', `comment_reply_ID` int(11) NOT NULL DEFAULT '0', `comment_subscribe` enum('Y','N') NOT NULL DEFAULT 'N', `openid` tinyint(1) NOT NULL DEFAULT '0', PRIMARY KEY (`comment_ID`), KEY `comment_post_ID` (`comment_post_ID`), KEY `comment_date_gmt` (`comment_date_gmt`), KEY `comment_approved_date_gmt` (`comment_approved`,`comment_date_gmt`), KEY `comment_parent` (`comment_parent`) ) |
There again several ways how to make the query more optimal, but let’s make a little exercise: Please
propose your solution in comments, and for the one I like the most by the end of February, I will give my personal discount code to Percona Live MySQL Conference and Expo 2014
So in the conclusion:
- Query Analytics from Percona Cloud Tools gives immediate insight as to which query requires attention
- With continuously running reports we can see the trends and effects from our optimizations
Please also note, that Query Analytics does not require you to install MySQL proxy, some third-party middle-ware or any kind of tcp-traffic analyzers. It fully operates with slow-log generated by MySQL, Percona Server or MariaDB (Percona Server provides much more information in slow-log than vanilla MySQL).
So try Percona Cloud Tools for free while it’s still in beta. You’ll be up and running minutes!
Actually, Would you like me to take look on your queries and provide my advice? It is possible.
I will be running a webinar titled “Analyze MySQL Query Performance with Percona Cloud Tools” on Feb-12, 2014; please register and see conditions.






Vadim,
Nice catch! I see couple of other interesting lessons in your post. I see you’re actually looking at _Maximum_ query time in this case which helps you to find this worse case scenario offending query which in our case is caused by specific blog post with lots of comments and is relevant. Solving the problem for this query now allow us to “futureproof” the application as chances are there are going to be increased number of blog post with large number of comments. It also shows the “Maximum Rows Examined” might be more stable metric to isolate such repeatedly bad queries as rows examined do not change because of load spikes, locks etc.
Another interesting observation is what there might be room for optimization which is not easily visible to the naked eye. In average those queries were not bad at 63ms execution time and you might not have spotted them until it becomes rather late.
Nice post 🙂
alter table wp_comments add index (comment_approved, comment_post_ID);
I suggest changing collocation for comment_author_email to something with _ci, removing lcase from the query, then index
KEY
my_most_loved_index(comment_author_email,comment_post_ID)1) The key_len seems to be wrong as it should be 28 instead of 62
comment_approved (20) + comment_date_gmt (8)
2) There is no need to change case of comment_author_email because the comparison will be not be case sensitive.
3) Covering index will make this query very fast.
alter table wp_comments add index (comment_author_email, comment_subscribe, comment_approved, comment_post_ID);
4) comment_subscribe is enum(‘Y’,’N’) then why not comment_approved enum(‘0’, ‘1’)? Why should it be varchar(20)?
Heh, I was always grinning a bit at how slow mysqlperformanceblog loaded for me.
Did you submit this patch to WordPress? All users could probably benefit!
There is discussion on WordPress.org triggered by this blog post
https://core.trac.wordpress.org/ticket/26858
We’re proud we could help a bit !
Thanks for this article, is so simple to analyse query !
You should do the same work with prestashop, i am sûre there are lot of buggy queries 🙂
SELECT comment_post_ID FROM wp_comments WHERE LCASE(comment_author_email) = ‘[email protected]’ AND comment_subscribe=’Y’ AND comment_approved = ‘1’ GROUP BY comment_post_ID
We have to add an index for comment_subscribe,comment_approved and comment_author_email. We can add comment_post_ID in it as last field, but this may decrease performance as well on writes and we can afford a little row reads for most emails. We don’t need lowercase as emails are case sensitive. We can change group by to select distinct.
SELECT distinct comment_post_ID FROM wp_comments WHERE comment_author_email = ‘[email protected]’ AND comment_subscribe=’Y’ AND comment_approved = ‘1’
Further optimization can be to make a second table to contain comment_content and other varchar/text fields we don’t need to search for. This will make a smaller table for searches and then we’ll read content blocks only when needed by primary key join:
select c.*, cd.content from wp_comments c join wp_commentscontent cd on c.comment_post_ID = 1 and c.comment_ID=cd.comment_ID
select c.*, cd.content from wp_comments c join wp_commentscontent cd on c.user_id = 1 and c.comment_ID=cd.comment_ID
Open source projects use a lot of left joins that’s a pain too. Normally something like
SELECT c.comment_post_ID,p.*,u.name,u.email, la.datelast FROM wp_comments c
left join wp_posts p on c.comment_post_ID=p.post_ID
left join wp_users u on c.user_id=u.user_ID
left join wp_useractivity la on u.user_ID=la.user_id
WHERE LCASE(c.comment_author_email) = ‘[email protected]’ AND c.comment_subscribe=’Y’ AND c.comment_approved = ‘1’ and p.deleted=0
GROUP BY c.comment_post_ID limit 10
which would make the MySQL query optimizer go crazy and can be easily transformed into
SELECT c.comment_post_ID,p.*,u.name,u.email, la.datelast FROM
(select distinct comment_post_ID from wp_comments
c.comment_author_email = ‘[email protected]’ AND c.comment_subscribe=’Y’ AND c.comment_approved = ‘1’
limit 10
) c
join wp_posts p on c.comment_post_ID=p.post_ID and p.deleted=0
left join wp_users u on c.user_id=u.user_ID
left join wp_useractivity la on u.user_ID=la.user_id
MySQL query quality in WordPress, SMF, Joomla, Prestashop, OSCommerce and so on is really bad. In fact most people don’t think about indexes, table structure(Normalization is not the best all the time if you put 100 varchar fields in one place, but forget you can have 5 ints for searches and then join to the main not searchable info.) and so on.
Thomas, just open the code and search for left joins(Most pain is in them.). Copy them to PMA and see the query execution time it shows. There’s no open source CMS that’s optimized in its SQL and doesn’t use large tables with tons of fields each, left joins. Creating indexes based on analysis of the queries you run lately is never used and there’s not a case when complex queries can run 100% based on indexes. That’s why 100000 topics with 600000 comments can make SMF go crazy(My last project is to add functionality to such a forum with 50-60 requests per second at max loads that just blocked for 5-6 seconds on high loads because of such queries even with a lot of memcached used by previous programmers who worked on it.) and normally this ammount of data is a game for MySQL. But, hell, they use string comparison in a field to see if someone’s reading a topic(100% full row scan) and have no simple int field for that, so only such a little change in code(the insert in online users table and the table itself plus the who’s viewing query) makes it run the query for 0.0001s rather than 0.03s on 5000 online users that’s a really small table. They just made it work for 10-100 online users in the open source.
Play a little with the main MySQL rule- one index for a single query on a table, and try to replace left joins with something else or just left join only when you have the rows you need from main query condition.
A query like
select * from comments where author=’atanas’ or email=’[email protected]’
when you have indexes for email and author makes a full table scan. If you change it to
select diestinct c.* from (
select * from comments where author=’atanas’
union
select * from comments where email=’[email protected]’
) c
You have two subqueries on a table which uses both indexes(One for each subquery.) and will run even thousands of times faster on large data. A simple explain will show the difference.
A really good thing to know also is that MySQL indexes can be used partially. If you need to get results for status, arhived, email, you can use the same index for getting by status and archived or status only.
Woa, I have a lot to learn ! Thanks
It may be a stupid question, but does it exist a mysql proxy where wen “rewrite” the query ? (Like Nginx proxy..) So we could optimize the query part without edit the CMS code directly.
Thanks for the exemple, its raining this weekend ;( so its a good time to play with Prestashop and Mysql ^^
I don’t know about such a proxy. There’s MySQL proxy, but it’s about load balancing and some more query caching. If it’s raining, search for “High performance MySQL” and read the chapters about query optimization. A great book for a cloudy day.
Dear Mr. Tkachenko,
thanks for your introduction of that tool. I will use it in future on my own WordPress installation.
My recommendation of optimizing the indices is the following one:
ALTER TABLE wp_comments ADD INDEX (comment_author_email, comment_subscribe, comment_approved, comment_post_ID)
The advantage of this solution is that the data could be calculated from the index. Disadvantage is that the index will take much space on the disc.
Hello,
1. What is the impact of creating index with 300 bytes size. How much table size (index size) increased?
2. Why in the second querry explain shows usage of 62 bytes while it has only 28 bytes?
Woa, so easy to install !!
I can see the listing of my queries but there is no way to “detect” bad queries automatically (maybe rows exa./sent ratio, index, times ….) or to order queries by times etc…
Maybe with background color red/green … to be more explicit, and give some optimization advice.
Also a console to execute query would be useful.
Krogon,
If you make a table with varchar(300) for mail and lately want to scan it fast, you have two options and this article is about the easier one- add an index. Yes, you loose disk space, slow down writes. The second way is denormalization. You can easily create a table id, email, name . Then you can use this id to point for user as int and index on that and also use the 300 char index on the table with unique emails/names. This will run times faster, but will need rewriting the CMS code itself, so I think the author has decided not to talk about it.
I saw there’s a webinar on 22.01 about further MySQL optimizations- denormalization, server configuration and so on. Let’s see what they’ll tell us there. Whatever it is, Percona are some of the very few with perfect knowledge on engines MySQL uses and the best ways to use them.
I was about to comment that a simple index on (comment_author_email, comment_post_ID) would make this query perform much better combined with the removal of the useless LCASE(). It’ll remove the need for using temporary/using filesort in the exec plan.
But jedrna_pamela beat me to it 😉