

One of the MySQL 5.6 features many people are interested in is Global Transactions IDs (GTIDs). This is for a good reason: Reconnecting a slave to a new master has always been a challenge while it is so trivial when GTIDs are enabled. However, using GTIDs is not only about replacing good old binlog file/position with unique identifiers, it is also using a new replication protocol. And if you are not aware of it, it can bite.
Replication protocols: old vs new
The old protocol is pretty straightforward: the slave connects to a given binary log file at a specific offset, and the master sends all the transactions from there.
The new protocol is slightly different: the slave first sends the range of GTIDs it has executed, and then the master sends every missing transaction. It also guarantees that a transaction with a given GTID can only be executed once on a specific slave.
In practice, does it change anything? Well, it may change a lot of things. Imagine the following situation: you want to start replicating from trx 4, but trx 2 is missing on the slave for some reason.
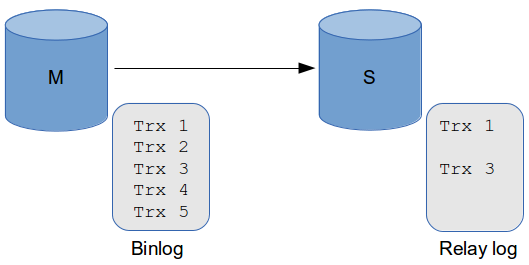
With the old replication protocol, trx 2 will never be executed while with the new replication protocol, it WILL be executed automatically.
Here are 2 common situations where you can see the new replication protocol in action.
Skipping transactions
It is well known that the good old SET GLOBAL sql_slave_skip_counter = N is no longer supported when you want to skip a transaction and GTIDs are enabled. Instead, to skip the transaction with GTID XXX:N, you have to inject an empty transaction:
1 2 3 | mysql> SET gtid_next = 'XXX:N'; mysql> BEGIN; COMMIT; mysql> SET gtid_next = 'AUTOMATIC'; |
Why can’t we use sql_slave_skip_counter? Because of the new replication protocol!
Imagine that we have 3 servers like the picture below:

Let’s assume that sql_slave_skip_counter is allowed and has been used on S2 to skip trx 2. What happens if you make S2 a slave of S1?
Both servers will exchange the range of executed GTIDs, and S1 will realize that it has to send trx 2 to S2. Two options then:
- If trx 2 is still in the binary logs of S1, it will be sent to S2, and the transaction is no longer skipped.
- If trx 2 no longer exists in the binary logs of S1, you will get a replication error.
This is clearly not safe, that’s why sql_slave_skip_counter is not allowed with GTIDs. The only safe option to skip a transaction is to execute a fake transaction instead of the real one.
Errant transactions
If you execute a transaction locally on a slave (called errant transaction in the MySQL documentation), what will happen if you promote this slave to be the new master?
With the old replication protocol, basically nothing (to be accurate, data will be inconsistent between the new master and its slaves, but that can probably be fixed later).
With the new protocol, the errant transaction will be identified as missing everywhere and will be automatically executed on failover, which has the potential to break replication.
Let’s say you have a master (M), and 2 slaves (S1 and S2). Here are 2 simple scenarios where reconnecting slaves to the new master will fail (with different replication errors):
# Scenario 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # S1 mysql> CREATE DATABASE mydb; # M mysql> CREATE DATABASE IF NOT EXISTS mydb; # Thanks to 'IF NOT EXITS', replication doesn't break on S1. Now move S2 to S1: # S2 mysql> STOP SLAVE; CHANGE MASTER TO MASTER_HOST='S1'; START SLAVE; # This creates a conflict with existing data! mysql> SHOW SLAVE STATUSG [...] Last_SQL_Errno: 1007 Last_SQL_Error: Error 'Can't create database 'mydb'; database exists' on query. Default database: 'mydb'. Query: 'CREATE DATABASE mydb' [...] |
# Scenario 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # S1 mysql> CREATE DATABASE mydb; # Now, we'll remove this transaction from the binary logs # S1 mysql> FLUSH LOGS; mysql> PURGE BINARY LOGS TO 'mysql-bin.000008'; # M mysql> CREATE DATABASE IF NOT EXISTS mydb; # S2 mysql> STOP SLAVE; CHANGE MASTER TO MASTER_HOST='S1'; START SLAVE; # The missing transaction is no longer available in the master's binary logs! mysql> SHOW SLAVE STATUSG [...] Last_IO_Errno: 1236 Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.' [...] |
As you can understand, errant transactions should be avoided with GTID-based replication. If you need to run a local transaction, your best option is to disable binary logging for that specific statement:
1 2 | mysql> SET SQL_LOG_BIN = 0; mysql> # Run local transaction |
Conclusion
GTIDs are a great step forward in the way we are able to reconnect replicas to other servers. But they also come with new operational challenges. If you plan to use GTIDs, make sure you correctly understand the new replication protocol, otherwise you may end up breaking replication in new and unexpected ways.
I’ll do more exploration about errant transactions in a future post.






Stephane,
I have couple of questions about this description
1) You say Slave sends all transaction IDs it has executed and Master sends back all transactions missing. But in practice we’re looking at Slave executing millions and billions of different transaction IDs how is it going to send that to the master ?
2) Send missing transaction is interesting. Lets say I have 1000 transactions and transactions number 5 gone missing for some reason. When slave connects and fetches transaction its changes can potentially conflict with some of the later transactions ? Now if we have full before-after row images we can detect if transaction can’t be executed now, however what is about Statement level replication ? Can we have potentially very old missed transactions to come to haunt us by doing update which was long overwritten ?
Peter,
1) Ranges of GTIDs are stored as GTID sets, which is a compact way to display large amounts of transactions. Like if slave N has executed trx 1 to 1M from server XYZ, the corresponding GTID set is XYZ:1-1000000. Have a look to the Executed_Gtid_Set field in the output of SHOW SLAVE STATUS.
2) You’re right. A missed transaction can come back and break replication because it conflicts with another transaction or because the binary log of the corresponding event has been purged. You can also have silent data corruption (an update statement executed a second time for instance). I’m writing another post to give more details regarding the dangers of errant transactions.
Thanks Stephane,
It looks to me like the worse case scenario could cause a lot of space and network traffic 🙂
About missing transaction – would ROW base replication be protected having before -after image at least for changed columns so if data was already changed the transaction would not go, right ?
Peter,
AFAIK a missing transaction is always re-executed (row-based or statement-based replication), but that should be easy to test.
Stephane.
Thanks for your nice article.
I’ve heard mysql 5.6 gtid replication never allow a transaction(gtid) hole.
So I can’t understand how the situation(second picture) can happen.
As you said, mysql 5.6 gtid managed with SET concept. So if mysql 5.6 allow gtid hole, then mysql 5.6 have to manage a lot of gtid set. But they don’t. They have only one gtid set for single mysql instance(I think).
In case of your second picture, what S2’s Gtid_executed field have ?
I think this case, show slave status result will be “Gitd_executed : host1_uuid:1,host1_uuid:3” (I think).
You mean “host1_uuid:1,host2_uuid:3” ?
Anyway thanks a lot .
Matt SeongUck.
Matt,
You’re right, the situation in the 2nd picture is not allowed to happen.
I wanted to explain that if we could create a hole with sql_slave_skip_counter, it would create problems. So if we want to skip a transaction, what we have to do is to execute a fake one.
By doing that, we have no hole in the sequence of GTIDs and we have been successful at not executing a specific transaction.
Matt,
Actually scenario 2 can happen. If master is running gtid and MTS, and crashes for some reason, we can have a situation where upon failover to slave, we find that former master has holes in it’s executed gtid set, while slave has the more complete set. Further more, in any situation where we have errent transactions on the slave and a failover occurs to that slave, we can have master applying errent transactions from slave out of order. This is what baffles me about gtid – it allows out of order execution of transactions even when replication format is statement based, thus resulting in slave drift.
Maybe someone could explain how this is not true and gtid does not cause slave drift when slave fetches some very old errent transaction and applies it?
Thank you
Jun