

For this post I’m going to shamelessly exploit the litany of technical problems SimCity players encountered earlier this month and a few examples of how Thread Pool for MySQL and Percona Server for MySQL can help to prevent such incidents.
Users of SimCity, a city-building and urban planning simulation video game, encountered network outages, issues with saving progress and problems connecting to the game’s servers following a new release a couple of weeks ago featuring a new engine allowing for more detailed simulation than previous games. During this same time, we happened to be testing the Thread Pool feature in Percona Server for MySQL, and I saw a connection of how Thread Pool is supposed to help in such cases.
Basically SimCity users faced the same situation San Francisco Bay Area commuters face every day — traffic gridlock, probably worst in the United States.

(the image is taken from izahorsky flickr)
There is also a well-known dependency from the queuing theory that shows the same thing: 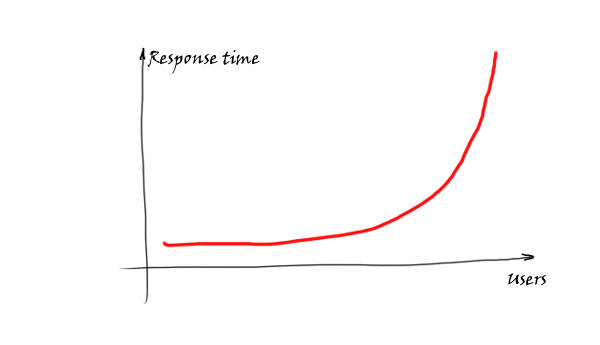
The more users who are trying to access a shared resource, the worse the response time is, growing exponentially.
To make things even worse, very often we see the following pattern with throughput.
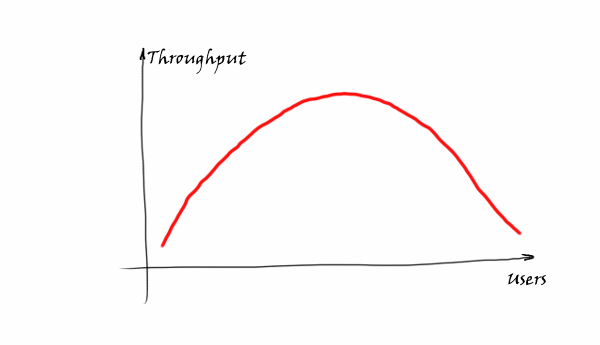
Basically the more users who are coming, the less requests/sec the system is able to handle. The reason is that working processes require internal communication and synchronization. At some point the system becomes unresponsive and practically stuck. Well-known DDoS attacks are based on this behavior — to load a system with so many requests that it is not able to proceed.
What is the solution here? If you allow me again an analogy with traffic: you have probably at some point encountered “on-ramp metering” solutions, traffic lights that throttle how many vehicles can enter a highway from an on-ramp during peak traffic times:
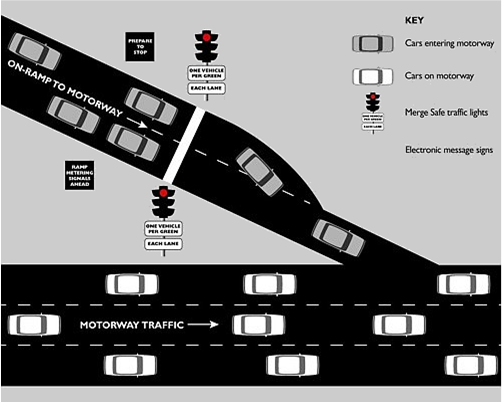
The intention of this solution is to provide smooth throughput when you are already on the highway.
The similar idea is behind Thread Pool for MySQL. We want to provide this kind of throughput:
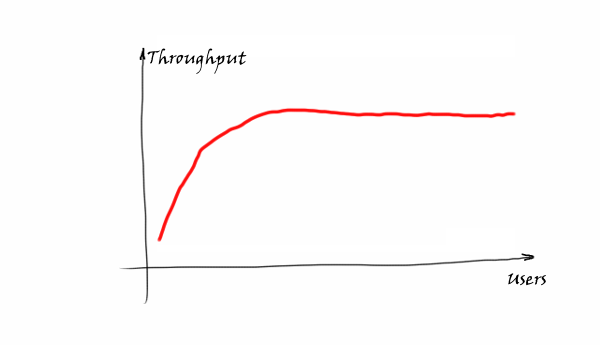
This is achieved by limiting the amount of working threads inside MySQL. So Thread Pool for MySQL does not improve the performance magically by itself, but it is rather a protection for cases when MySQL may become suddenly overloaded.
The Thread Pool feature is available in Percona Server 5.5.30 and Percona Server 5.6.10-alpha and there are some reports from users with visible improvements, i.e:
“Percona thread pool in the real world, tremendously improves lock convoy issues: http://buff.ly/12FUiYf , Activated on 7th around noon”

While a similar plugin is available from Oracle by MySQL Enterprise subscription, you can get it and try it with Percona Server for MySQL right now for free.
UPDATE from 3/21/2013 on Credits: The current implementation of Thread Pool in Percona Server is taken from MariaDB and was developed by Vladislav Vaintroub. The commercial implementation is developed in Oracle/MySQL and I do not know who original author is.






Awesome illustration with the traffic scenario.
This post does shed more light on how a thread pool can help. Will have to check it out.
Thank you.
It’s nice to see that the thread pool gives Simsity a much needed performance boost. Of course, this was the scenario it was created for!
However, the credit for the this work should be given to Vladislav Vaintroub who implemented this originally for MariaDB 5.5.
It’s very nice to see the code get into the Percona server, but it’s bad that Percona, again, forgets to give credit where credit is due.
Michael,
Good to see you on our blog, but it is sad to hear a false accusations.
We give credits to MariaDB in our Release Notes
https://www.percona.com/doc/percona-server/5.5/release-notes/Percona-Server-5.5.29-30.0.html
SimCity is a great example for a complete and utter train wreck of not only a product launch but also communication with the customers. First they introduced features that fans of the series did not want, then those features didn’t work and then they fed a stream of lies in corporate communication that were promptly discredited.
@Vadim Tkachenko very good explanation and article. Regarding MariaDB: the issue is not about the release notes but about a high traffic site that mentions lots of Percona product information as though it were not a Percona sponsored and employee run site, and then in the article does not give credit to the original coder which is, coincidental, a competitor of Percona. So to those not taking the time to read the code release notes, but are reading a very popular site about MySQL performance, it is respectful to give credit where it is due and not make Percona (again, again, again) look like they invented something for MySQL that has existed before.
You mentioned the thread pool option is available in 5.5.30
Is it available before that? I’m seeing that variable in 5.5.25a. Or does the functionality behind it just not work?
mysql> select version()\G
*************************** 1. row ***************************
version(): 5.5.25a-27.1-log
1 row in set (0.00 sec)
mysql> show variables like ‘%thread_handling%’\G
*************************** 1. row ***************************
Variable_name: thread_handling
Value: one-thread-per-connection
1 row in set (0.00 sec)
I think I answered my own question by checking ‘thread_pool_oversubscribe’. Looks like its not on 5.5.25a
The thread_handling variable is a legacy of the first version of this type of code that was produced in 5.0.x for a MySQL customer in 2007 that I worked with. While this was a custom build, this variable definition (and effectively no use other then information) was pushed into the main line while the code was never pushed.
@Ronald … interesting to know. Can you tell us a bit more about how the first version of the code worked and why it didn’t get merged into the base? It’s a great system to have so I’m curious if the one you coded solved the client’s needs and then, perhaps, was proprietary and not mainlined or something.
@Matt Yonkovit, legally I believe there is sufficient time from my original contact, and information freely available to discuss publicly.
The Thread Pool code was originally written by a very smart engineer at eBay who’s name escapes me. Because eBay wanted to have a supported version of this code, it was agreed that Monty would rewrite this and MySQL Inc would provide a supported MySQL binary. (I was in the room with Monty when he detailed how long this would take).
I was also the first MySQL Consultant from MySQL Inc to work at eBay on an extended basis in 2007. (as a side story I lived in NY on weekends and worked in SF during the week for several months) In 2008, eBay both won a Community Award and presented that the O’Reilly conference on their first deployed MySQL system. See http://ebayinkblog.com/2008/04/15/ebay-wins-application-of-the-year-at-mysql-conference-expo/ for more information.
Now, a bit more about the code itself is mentioned on an eBay blog at http://www.ebaydba.net/?p=101, and gives you an indication of the numbers of database connections the thread pool supported.
I was not part of the original conversation, but I was told that eBay paid for the work on the agreement that the code would be able to all in the next open source version (that would be 5.1). We all know that did not happen, so now by saying this I will have started a likely flame war discussion.
The purpose behind the feature is clear, and Vadim gives a good general description of the problem. I would again highlight the reason for it’s purpose is to reduce the internal communications between the kernel and the threads, as with too many threads, the system spends more time managing threads and context switching then actually doing work.
I am not at liberty to detail specifics, and much has changed in a 6 years in code base and MySQL versions, but it was very surprising to find out just few threads in a thread pool were necessary to supports tens of thousands of actual connections.
As with any functionality, testing and benchmarking is necessary.
I would also caution people to clearly understand and test, what are “connections” and what are “active connections” when determining a thread pool size.
FYI, it was really hard to do a SHOW PROCESSLIST with so many connections.
@Ronald, thanks for the detail. I read the posts you linked but would love to know more about how/why the thread pool is only now being integrated as it is. I remember hearing a lot of hype about it years ago but it seemed to be vaporware at its finest — so generally the solution I presented to clients was a MySQL connection pool handling system for the application level via a lightweight python app (using multi threading and internal queues) that accepted connections from the app (php, java, python, etc) and then passed the traffic over to the DB server. This was effectively a SQL proxy but it offered an easy way to handle connection pooling and throttling so that connection spikes could be smoothed out; perhaps one day soon it can be open sourced as well.
Regarding the 30k connections and show processlist — that reminds be of a client I supported and designed their MySQL infrastructure (now an acquired subsidiary of a larger entity) that was, at the time, running 10k concurrent connections and over 20k QPS on the master, which equated to serving >1B ad impressions per day on a 8-core DL380 with 32GB RAM. Back in 2006 I recall that being an impressive number and it would have been especially suited for a NoSQL implementation given how the schema was designed, which was part of how we were hitting high concurrency without falling over on 5.0.27. Of course now it’s common to see much higher numbers from NDB and 5.5.x clusters with not just simple queries or simple transactions but high concurrency with complex transactions as well — items like the thread pool offering far more sanity and stability than life back in the days of MySQL 5.0.x.
On that end, I’m in the process of tests that aim to show just how far things have come with MySQL clustering performance: http://themattreid.com/wordpress/2013/03/01/building-a-mysql-private-cloud-step-1/ — this will be a series of posts over time (as I have spare time for non-work related fun load tests that is..) which is going to show from start to finish how to build a private cloud service that can be used to host rapidly scalable NDB clusters (commence with inserting a shameless plug that users can then buy such private clouds from https://virtualprivateinternet.com pre-built as a package once I finish the articles explaining how it all works)
As an aside, setting the pager to ‘less’ is a useful bit when running show processlist on high connection servers 🙂
I can broadly confirm Ronald’s depiction of events. There are a few key reasons for these “non-recurring engineering” (a new feature paid for by a specific client) things having tended to not be integrated into the main server (for a long time).
Firstly – while the NRE was paid for, the subsequent integration is not. Thus it’s a task that developers need to do on internal company time, which at that time (in MySQL AB) was aggressively driven by sales. They did not get the time to do these things (nor many other things that were important for quality but didn’t directly drive more $).
Secondly – several features were engineered in a rush because of lack of listening by sales people to the developers who would actually do the work – thus while it was a sale, it would be inadequately estimated and thus the developer wouldn’t get proper time to do so with the demand to deliver. Aggressive sales tends to over-sell, and thus inevitably under-delivers.
When a feature is hacked in like that, it might be usable for the one specific client, but it’s not engineered in such a way that it’s suitable (or even safe) for the server code in general, and in a maintainable way. Other examples of this have been where consultants or sales engineers who had skill and familiarity with the codebase but not with the development process, would implement a feature.
In short, the fact that there was a chunk of code that had been paid for by a client, didn’t mean that it was usable in general. That of course is an important failure, and ultimately to the detriment of the client as well. Why? Because if the code is not in mainline, it always remains a patch for that one client – they could spend time on it internally for every update, or pay for some else to do the same, but the cost is ongoing and some time later it (with core code changes) it’d become impossible. And then it’s a dead piece of code, and the enhancement is lost for everyone.
Integration into mainline therefore always has to be part of the deal. A good early example of this is classic MySQL replication, which was implemented by Sasha Pachev at MySQL AB around 1999, paid for by a specific client. They needed it, but it was built to be in mainline. Now we can argue about effectively code quality (“Sasha code”), but at least the approach was right and while replication is not perfect, it’s done brilliantly well for tens of millions of deployments and helped companies scale in a way that would otherwise not have been possible.
The Thread Pool feature IMNSHO is one of the many victims of a borked sales driven development process.
Another example could be stored procedures. They were put in as “tick box requirement” again driven by sales, and the initial implementation was not pretty. Mark Callaghan calculated once that the 5.0 parser was up to 20% slower overall, merely because of the extra syntax having been added in a sloppy way. He showed how, when done differently, it didn’t have that problem. There were many other aspects to it, leading Brian Aker to decide to rip out that entire chunk of code when working on Drizzle. Stored Procedures have their use today, but it’s not difficult to identify and acknowledge these aspects and problems.
Vadim, I think your throughput curve is inaccurate – to the point where it doesn’t give an adequate image of what’s going on.
It shouldn’t be a bell curve, the performance doesn’t degrade gracefully at all. It plummets. So after the peak, it will degrade a little bit and then go pretty much straight down.
We can go into a deeper discussion of why this is the case, but I’m pretty sure you’ll agree with me on this anyway.
@Matt Yonkovit,
That is a fair point about credits. I updated the post to reflect recommendations.
@Arjen,
I think the curve depends on many factors, my goal of hand-drawn curve was to show that sooner or later it will get back almost to zero.
We will run benchmarks with Thread Pool vs no-Thread Pool so we will see exact curve there.
Also some idea about curve you can see from theoretical models, i.e.:
http://www.mysqlperformanceblog.com/2011/02/28/is-voltdb-really-as-scalable-as-they-claim/
Some of the comments refer to the older eBay-sponsored thread pool implementation. Is it the same implementation that was available in MySQL 6.0.x branches, and, IIRC, was merged to MariaDB before the current implementation? IIRC it didn’t have the “thread is waiting now” annotations, it used single-threaded libevent and had to serialize on LOCK_thread_count or some other global mutex to do its work.